CPU Pipeline
여기서는 Pipeline의 효율 최대화를 위한 코드 재배치에 대해 알아볼 것이며, Pipeline Hazard, RISC, CISC에 관한 내용은 생략합니다.
개요
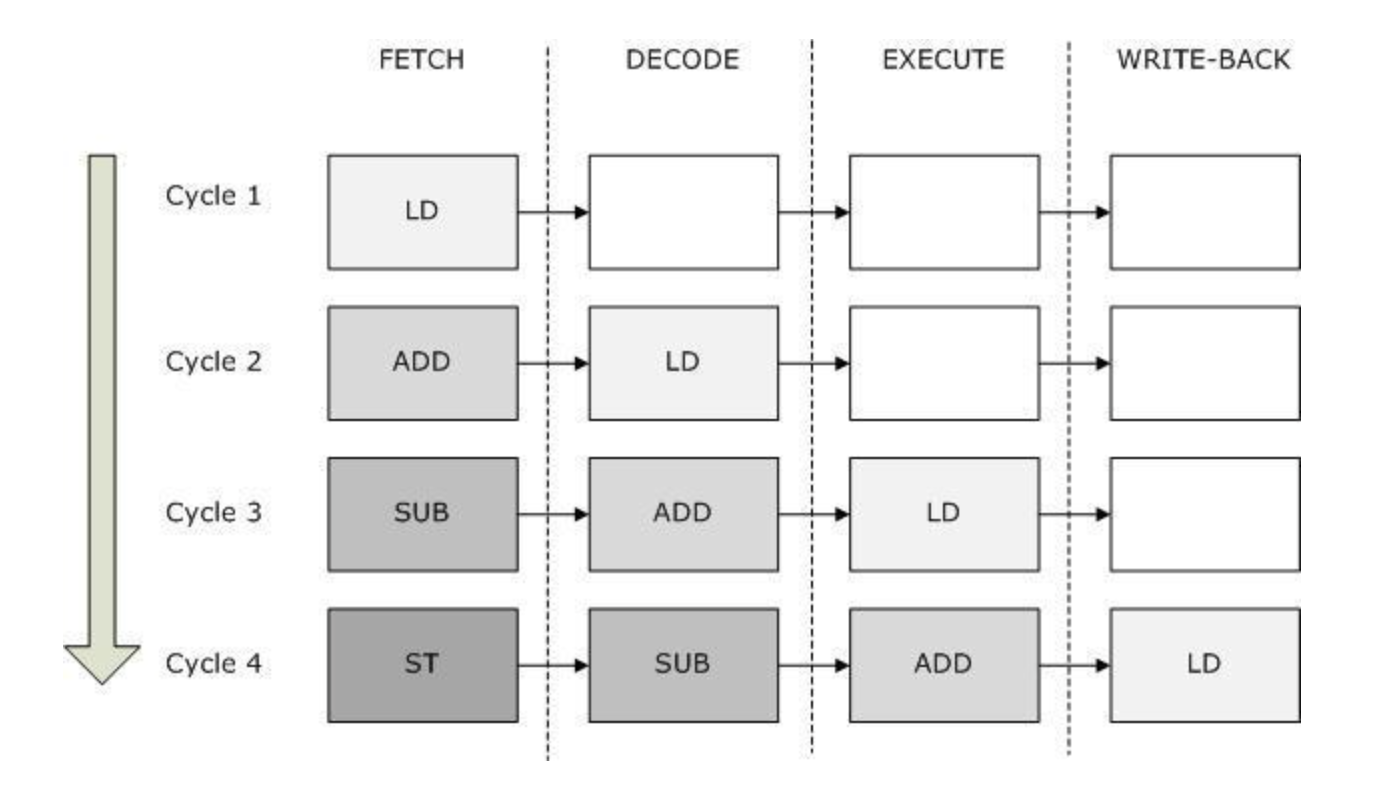
- CPU가 연산 속도를 향상시키고 노는 시간을 최대한 줄이기 위해 CPU 파이프라인을 도입한다는 사실은 익숙하다.
- CPU는 각 연산 모듈(ALU 등)간 연산 속도, Task당 분배해야하는 시간 등을 고려하여 속도를 최적화 시키기 위해 로직이 엉키지 않는 선에서 코드 재배치를 수행한다.
- 일반적인 상황(싱글 쓰레드 = 중량 프로세스)에서는 이러한 코드 재배치가 논리 구조를 건드리지 않는 선에서 동작하기 때문에 문제를 일으키지 않지만, 멀티 쓰레드 환경에서는 이야기가 조금 다르다.
- 쓰레드간 논리 구조가, CPU의 코드 재배치에 의해 엉키게 되면, 나와선 안되는 결과가 나올 수 있다. 따라서 우리는 이러한 코드 재배치를 신경쓰며 멀티 쓰레드 프로그래밍을 해야 한다.
예제 코드
#include <iostream>
#include <atomic>
#include <mutex>
#include <windows.h>
#include <future>
using namespace std;
int32 x = 0;
int32 y = 0;
int32 r1 = 0;
int32 r2 = 0;
volatile bool ready;
void Thread_1()
{
while(!ready);
y = 1; // Store y
r1 = x; // Load x
}
void Thread_2()
{
while(!ready);
x = 1; // Store x
r2 = y; // Load y
}
int main()
{
int32 count = 0;
while(true)
{
ready = false;
count++;
x = y = r1 = r2 = 0;
thread t1(Thread_1);
thread t2(Thread_2);
ready = true;
t1.join();
t2.join();
if(r1 == 0 && r2 == 0)
break;
}
// Break로 빠져나온 경우
cout << cout << " 번만에 빠져 나옴" << endl;
return 0;
}
r1 == 0 && r2 == 0인 상황이 로직상 발생하면 안된다.- 그런데 while문을 어떻게 빠져나오는거지?
문제
- 가시성 :
- 캐시 정책에 따라 프로세서는 자신이 데이터를 변경한 기록을 캐시에만 저장할 수도 있고, 메모리까지 가서 저장할 수도 있다.
- 마찬가지로 데이터를 가져올때,
cache miss발생시, 데이터를 가져와 캐시에 넣고 쓸 수도 있고, 그냥 바로 메모리 값만 가져올 수도 있다. - 모든 내용은 앞서 말했듯 칩 별 캐시 정책에 따라 다르기 때문에 일반화하는 것은 불가능하다.
- 멀티 프로세싱에서 코어 별로 따로 캐시를 가지고 있기 때문에, 각 코어마다 같은 변수를 동시에 써도 서로 다른 값이 나올 수도 있다!! (캐시에만 쓰기 완료된 데이터를 넣었다면)
- 코드 재배치 :
- CPU Pipeline의 효율성을 극대화 하기 위해 코드의 위치를 일부 수정하는 것.
- 상기 개요에서 설명한 내용과 같다.
-
y = 1; // Store y r1 = x; // Load x 위 코드를 제멋대로 아래 코드로 바꿀 수 있다. r1 = x; // Load x y = 1; // Store y
Memory Model
🤔 무엇을 믿어야 할까?
- C++11에서 추가된 가장 중요한 것? Memory Model
atomic 연산에 한해, 모든 쓰레드가 동일 객체에 대해서 동일한 수정 순서를 관찰
- atomic 연산이란, 단순히
atomic<typename T>클래스만을 의미하는 것이 아니라, CPU Instruction이 한 개처럼(또는 한 개인) 동작하는 연산을 의미함. - 동일 객체가 아니라면, 즉 서로 다른 객체가 존재하면, 다른 객체 간 순서는 보장되지 않음.
원자적 연산을 지원하는지 확인하는 방법
{
atomic<int64> v;
cout << v.is_lock_free() << endl; // 1
}
{
struct Knight
{
int32 level;
int32 hp;
int32 mp;
};
atomic<Knight> v;
cout << v.is_lock_free() << endl; // 0
}
💡 Lock Free = 락에서 자유롭다 = 락 안써도 돼~
is_lock_free()가 true라면, 사용중인 칩에서 해당 데이터 타입에 대한 원자적 연산을 지원함을 의미함.- int64는 원래 쓸 수 있지만, 네가 만든 Knight는 원래 못써. 내가 쓸 수 있게 구현해줄게
Memory Model 정책
atomic<bool> flag = false;
int main()
{
// flag = true; 문제가 생기진 않음
// flag.store(true);
flag.store(true, memory_order::memory_order_seq_cst);
// bool val = flag;
// bool val = flag.load();
bool val = flag.load(memory_order::memory_order_seq_cst);
// 이전 flag 값을 prev에 넣고, flag 값을 수정
{
/*
아래 코드는 비 원자적이기 때문에 다른 쓰레드에 의해 의도치 않은 상황 발생할 수 있음
bool prev = flag;
flag = true;
*/
bool prev = flag.exchange(true);
}
// CAS (Compare-And-Swap) 조건부 수정
{
bool expected = false;
bool desired = true;
flag.compare_exchange_strong(expected, desired);
}
}
flag.store(true)로 쓰면 디폴트 정책인flag.store(true, memory_order::memory_order_seq_cst)이 선택된다.
- Sequentially Consistent (seq_cst)
- Acquire-Release (acquire, release)
- Relaxed (relaxed)
- seq_cst (가장 엄격 = 컴파일러 최적화 여지 적음 = 직관적 = 재배치에 보수적)
- release - acquire (~ release ... acquire ~ 에서 ~에 해당하는 부분의 재배치 이루어지지 않음)
- relaxed (자유롭다 = 컴파일러 지 맘대로)
- 외에도
atomic_thread_fence()같은 것도 있지만 잘 사용하진 않는다.