Chap 12. 클러스터 관리

리소스 관리
앞서, Pod의 resource property를 통해 리소스를 관리하는 방법에 대해 알아보았다. 이번에는 LimitRange, ResourceQuota와 비교하며 차이점을 알아보자.
쿠버네티스 사용자를 크게 일반 사용자(developer)와 관리자(admin)으로 나누어 생각하면, 일반 사용자는 자신이 개발한 어플리케이션을 쿠버네티스 플랫폼 위에 실행하는 사용자이다.
관리자는 쿠버네티스 클러스터 자체를 관리하고 필요한 물리 리소스(노드, 디스크, 네트워크 등)를 제공하는 총 책임자 이다.
이 두 역할을 한 사람이 다 맡을 수도 있지만, 서로 다른 사람이 맡을 수도 있다. 이때, 클러스터 관리자가 일반 사용자에게 리소스 사용량을 제한하기 위해 사용하는 것이 LimitRange와 ResourceQuota리소스 이다.
LimitRange
LimitRange의 기능은 2가지이다.
- 일반 사용자가 리소스 사용량 정의를 생략하더라도 자동으로 Pod의 리소스 사용량을 설정한다.
- 관리자가 설정한 최대 요청량을 일반 사용자가 넘지 못하게 제한한다.
LimitRange는 일반 사용자의 Pod 리소스 설정을 통제하는 리소스이다. 예제와 함께 살펴보자.
일반적으로 리소스 설정 없이 Pod를 생성하면 다음과 같이 리소스 제약 없이 무제한으로 노드의 전체 리소스를 사용할 수 있다.
kubectl run mynginx --image mynginx
kubectl get pod mynginx -o yaml | grep resources
이 경우, 일반 사용자가 생성한 Pod가 노드 전체의 리소스를 고갈시킬 위험이 있다. 이를 방지하기 위해 클러스터 관리자가 네임스페이스에 LimitRange를 설정한다.
apiVersion: v1
kind: LimitRange
metadata:
name: limit-range
spec:
limits:
- default:
cpu: 400m
memory: 512Mi
defaultRequest:
cpu: 300m
memory: 256Mi
max:
cpu: 600m
memory: 600Mi
min:
memory: 200Mi
type: Container
- default: 생략 시 사용되는 기본 limit 설정이다.
- defaultRequest: 생략시 사용되는 기본 request 설정이다.
- max: 일반 사용자가 요청할 수 있는 최대치를 설정한다.
- min: 일반 사용자가 요청할 수 있는 최소치를 설정한다.
default 네임스페이스에 LimitRange를 설정한 다음, 다시 리소스 설정 없이 Pod을 생성해보자
⭐️ LimitRange는 NameSpace에 귀속되어 해당 NameSpace에서만 영향력을 발휘한다.
kubectl apply -f limit-range.yaml
kubectl run nginx-lr --image nginx
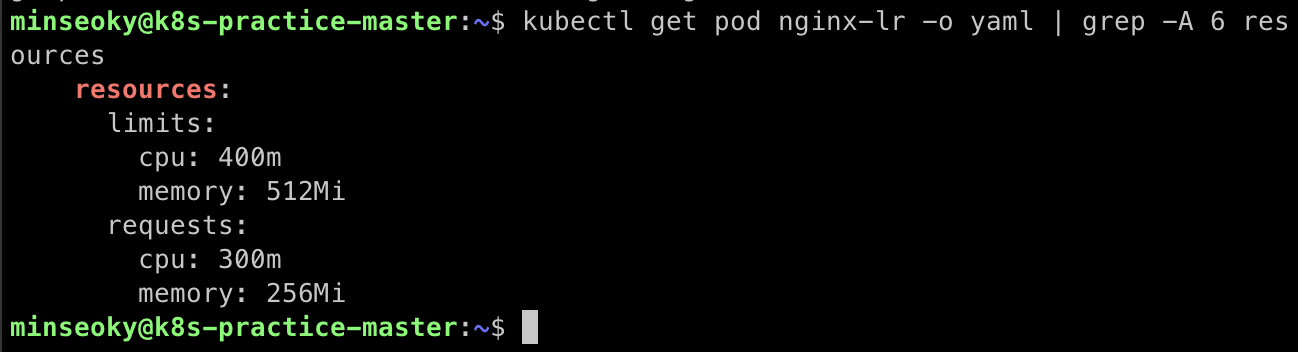
kubectl get pod nginx-lr -o yaml | grep -A 6 resources
# resources:
# limits:
# cpu: 400m
# memory: 512Mi
# requests:
# cpu: 300m
# memory: 256Mi
만약 사용자가 LimitRange의 max property에서 설정한 request, limit을 벗어난 리소스를 설정해서 Pod 생성 요청을 하면, 에러가 발생한다.
ResourceQuota
LimitRange는 개별 Pod 생성에 관여했다면 ResourceQuota는 전체 네임 스페이스에 대한 제약을 설정할 수 있다.
클러스터 관리자가 특정 네임스페이스의 전체 리소스 사용량을 제약하고 싶을 때 ResourceQuota를 설정한다.
LimitRange만 사용하는 경우, 1개의 Pod을 생성할 때 리소스를 제약할 수 있지만 이 Pod을 여러개 만들 경우, 마찬가지로 클러스터의 리소스를 전부 소진시킬 위험이 있다.
이것을 방지하기 위해 네임스페이스 자체에 전체 Quota를 설정한다. 다음과 같이 ResourceQuota를 default 네임스페이스에 설정한다면 네임스페이스 전체 총합의 명시된 limit과 request의 크기를 넘길 수 없다.
apiVersion: v1
kind: ResourceQuota
metadata:
name: res-quota
spec:
hard:
limits.cpu: 700m
limits.memory: 800Mi
requests.cpu: 500m
requests.memory: 700Mi
- limits.cpu: 네임스페이스의 CPU limit 총합을 제한한다.
- limits.memory: 네임스페이스의 메모리 limit 총합을 제한한다.
- requests.cpu: 네임스페이스의 CPU request 총합을 제한한다.
- requests.memory: 네임스페이스의 메모리 request 총합을 제한한다.
⭐️ ResourceQuota 또한 NameSpace에 귀속되어 해당 NameSpace에서만 영향력을 발휘한다.
노드 관리
쿠버네티스로 서비스 운영 시에 리소스 관리뿐만 아니라, 노드 자체에 대한 관리가 필요한 경우가 있다. 온프레미스 환경에서는 물리적인 디스크의 손상, 내부 네트워크의 장애가 있을 수 있고 클라우드 서비스인 경우에는 서버 타입 변경, 디스크 교체 등으로 인하여 노드를 일시적으로 중단하고 관리해야 하는 경우가 있다.
이런 상황에 대비하여 쿠버네티스는 특정 노드를 유지보수 상태로 전환하여 더는 새로운 Pod가 스케줄링 되지 않게 설정할 수 있다.
| 작업 명령어 | 설명 |
|---|---|
| Cordon | 노드를 유지보수 모드로 전환한다(SchedulingDisabled). |
| UnCordon | 유지보수가 완료된 노드를 다시 정상화한다. |
| Drain | 노드를 유지보수 모드로 전환하며, 기존의 Pod들을 퇴거(Evict)한다. |
Cordon
kubectl cordon <NODE>
특정 노드를 유지보수 모드로 전환하기 위해 cordon이라는 명령을 사용한다.
cordon의 사전적 의미는 '저지선을 치다, 사람들의 출입을 통제하다'이다. 노드에 더 이상 Pod가 출입하지 못하게 통제하는 것을 의미한다. 해당 명령어로 노드를 유지보수 모드로 전환하면, taints로 다음과 같이 설정이 붙게 된다
spec:
taints:
- effect: NoSchedule
key: node.kubernetes.io/unschedulable
timeAdded: "2020-04-04T11:04:48Z"
unschedulable: true
이 상태에서 Pod을 생성하면 더 이상 해당 노드에 Pod이 배치되지 않는 것을 볼 수 있다.
⚠️ 유지보수 상태인 노드에 명시적으로 nodeSelector 등을 이용해서 Pod를 배치하려고 하면 Pending 상태로 남게 된다.
UnCordon
kubectl undordon worker
cordon 한 노드를 원상복구시킨다. 다시 Pod들이 해당 노드에 스케줄링 가능한 상태가 된다.
Drain
노드를 cordon하면 새로운 Pod가 더 이상 할당되지는 않지만, 기존에 돌고 있는 Pod에 대해서는 관여하지 않는다.
기존에 실행되고 있는 Pod들도 퇴거시키기 위해서는 drain 명령을 사용한다. drain 명령은 Pod가 더는 할당되지 않게 taint 시킬 뿐만 아니라, 기존의 Pod들도 퇴거시킨다.
kubectl drain worker --ignore-daemonsets
- worker: 노드 이름
- --ignore-daemonsets: 모든 노드에 존재하는 DemonSet은 무시한다.
drain된 노드도 uncordon 명령을 통해 복구 가능하다.
Pod 개수 유지
drain 명령 시, Pod는 바로 종료된다. 비록 Deployment 리소스가 새로운 Pod을 생성해 주겠지만 일시적으로 Pod의 개수가 현격히 줄어들 수 있다.
이런 상황에서 응답 지연을 방지하기 위해, PodDisruptionBudget(PDB) 이 만들어졌다.
쿠버네티스에서 클러스터 관리자가 의도를 가지고 Pod을 중단하는 것을 Voluntary Disruptions(자진 중단) 이라 부른다.
장애로 인해 갑자기 Pod가 중단된 것이 아니기 때문에 사전에 알 수 있다. PDB는 노드 유지보수 작업을 위해 자진 중단한 상황에서 Pod의 개수가 일정 수준 이하로 내려가지 않게 막아주는 역할을 한다.
💡 PodDisruptionBudget 동작 방식
PDB는
minAvailable또는maxUnavailable값을 기준으로 Pod의 최소 가용 개수를 정의한다. 예를 들어minAvailable: 2로 설정하면, 남아 있는 Pod 개수가 2개 이상일 때만 drain 등의 자진 중단 작업이 진행될 수 있다. 반대로maxUnavailable: 1로 설정하면, 동시에 중단될 수 있는 Pod 개수가 최대 1개로 제한된다.drain 명령은 이 예산(PDB)을 만족하지 못하면 실패하게 되며, 관리자는 예산에 맞게 조정한 후 다시 drain을 시도해야 한다.
다음은 예시이다:
apiVersion: policy/v1 kind: PodDisruptionBudget metadata: name: nginx-pdb spec: minAvailable: 9 selector: matchLabels: app: nginx위 설정은
app=nginx라벨을 가진 Pod이 9개 이상 유지되어야만 drain이 진행될 수 있음을 의미한다.
kubectl drain <노드명> --ignore-daemonsets
이 명령은 다음을 수행한다:
- 해당 노드를 cordon 상태로 만든다 (새로운 Pod이 더 이상 이 노드에 할당되지 않게 함)
- minAvailable 조건에 맞다면 해당 노드에 있는 Pod들을 하나씩 종료(Eviction) 시킨다 • 단, --ignore-daemonsets 옵션으로 DaemonSet은 예외 처리
- 종료된 Pod가 Deployment, ReplicaSet, StatefulSet 등 컨트롤러의 관리 대상일 경우, 컨트롤러가 이를 감지하고 새로운 Pod을 다른 노드에 재생성한다
- 컨트롤러가 없거나 static pod이라면, 다시 스케줄되지 않음