Chap 2. 쿠버네티스 소개

쿠버네티스란?
💡 이전에 나루었던 내용과 겹치는 부분이 있지만, 스터디 목적으로 복습할겸 쿠버네티스에 대한 대략적인 내용을 다시 기술해봅니다.
쿠버네티스는 컨테이너 오케스트레이션 도구로, 여러 컨테이너를 체계적으로 관리하는 도구 중 하나다. 쿠버네티스를 사용하면, 컨테이너의 배포, 확장 및 스케줄링을 자동화할 수 있다.
쿠버네티스의 역사
쿠버네티스(Kubernetes)는 그리스어로 “키잡이(helmsman, κυβερνήτης)” 를 의미하며, 조 베다(Joe Beda), 브랜든 번스(Brendan Burns), 크레이그 맥루키(Craig McLuckie) 가 Google에서 내부 프로젝트인 Borg를 기반으로 설계한 컨테이너 오케스트레이션 시스템이다. 이후 Cloud Native Computing Foundation(CNCF) 에서 오픈소스로 관리되며 현재까지 발전을 이어가고 있다.
쿠버네테스의 설립자들
1. 조 베다 (Joe Beda)
• 깃허브(GitHub): @jbeda
• 트위터(X): @jbeda
• 블로그: http://blog.jbeda.com/
• 현재 활동: Heptio 공동 창립자 → VMware에 인수됨. 현재 Kubernetes 및 클라우드 네이티브 기술에 대한 조언 및 컨설팅 활동 중.
2. 브랜든 번스 (Brendan Burns)
• 깃허브(GitHub): @brendandburns
• 트위터(X): @brendandburns
• 현재 활동: Microsoft Azure에서 Kubernetes 및 클라우드 네이티브 기술을 주도하는 역할 수행.
3. 크레이그 맥루키 (Craig McLuckie)
• 트위터(X): @cmcluck
• 현재 활동: Heptio 공동 창립자 → VMware에서 Kubernetes 관련 기술을 발전시키는 역할 수행.
컨테이너 오케스트레이션이란?
다수의 서버 위에서 컨테이너의 전반적인 생명주기를 관리해주는 플랫폼을 통칭한다.
쿠버네티스는 대표적인 컨테이너 오케스트레이션 플랫폼이다. 구체적인 기능은 다음과 같다.
- 컨테이너의 실행 및 배포의 책임
- 이중화 및 가용성 보장
- Scale-Out, Scale-In(Horizontally)
- 각 컨테이너의 Scheduling 관리
- 네트워크 설정 관리
- 헬스체킹
- config 관리
데이터 센터 운영체제
쿠버네티스를 데이터 센터(클러스터) 운영체제라고도 부른다. 데이터 센터는 여러 서버를 연결하여 하나의 시스템처럼 동작하게 하는 컴퓨터의 집합을 의미한다. 운영체제가 하드웨어에 대한 추상화된 인터페이스를 제공하듯, 쿠버네티스도 여러가지 클러스터 자원에 대한 추상화된 인터페이스를 제공한다.
쿠버네티스의 기본 개념
애완동물 vs. 가축
 쿠버네티스틑 각 서버를 애완동물보다는 가축에 가깝다고 비유한다. 애완동물이 세심한 관리가 필요하고, 정해짐 이름이 있는 것과 달리, 가축은 떼로 방목하여 키우고, 죽는것에 (애완동물에 비해)크게는 신경쓰지 않는다.
쿠버네티스틑 각 서버를 애완동물보다는 가축에 가깝다고 비유한다. 애완동물이 세심한 관리가 필요하고, 정해짐 이름이 있는 것과 달리, 가축은 떼로 방목하여 키우고, 죽는것에 (애완동물에 비해)크게는 신경쓰지 않는다.
쿠버네티스는 서버마다 특별한 이름을 부여하지 않는다. 서버마다 특정 역할이 정해져있지 않기 때문이다. 쿠버네티스에서는 단순히 서버를 마스터와 워커로만 구분된다.
⚠️ 책에서 발췌한 해당 내용은,
taint,toleration, 혹은node affinity관련 개념과 조금 모순적인 것 같다. ex) 인공지능을 위한 고성능 GPU 서버 같은 경우는 의도적으로 서로 다른 서버로 분리하여 관리하기도 한다.
바라는 상태(Desired State)
쿠버네티스는 “바라는 상태(desired state)” 를 선언하고, 이를 자동으로 유지하려는 철학을 따른다. 이 개념은 “선언형(Declarative)” 접근 방식과 연관되며, 사용자는 어떤 상태가 되어야 하는지를 정의하고, 쿠버네티스가 이를 보장하도록 조정(Reconciliation)한다. 예를 들어, Deployment에서 레플리카 개수를 3개로 선언하면, 쿠버네티스는 장애 발생 시 자동으로 복구하여 항상 3개를 유지한다. 즉, 사용자는 “어떻게(How)“가 아니라, “무엇(What)“을 원하는지만 설정하면 된다.
컨트롤러
사용자가 바라는 상태를 선언하면, 쿠버네티스는 현재 상태를 사용자가 바라는 상태로 변경시킨다. 현재 상태를 바라는 상태로 변경하는 주체를 컨트롤러라고 부른다. 컨트롤러는 control-loop라는 루프를 돌며 특정 리소스를 지속적으로 모니터링한다.
쿠버네티스 리소스
쿠버네티스에서는 모든 것이 리소스 로 표현된다. Pod, ReplicaSet, Deployment 등 쿠버네티스에는 다양한 리소스가 존재하고 각각의 역할이 있다. 그 중에서도 Pod은 쿠버네티스의 최소 실행 단위 이다.
선언형 커맨드(Declarative Command)
바라는 상태에서 이야기했던 것처럼, 쿠버네티스는 선언형(Declarative) 방식으로 리소스를 관리할 수 있다. 사용자는 어떤 상태가 되어야 하는지를 YAML 파일로 정의하고, 이를 kubectl apply 명령어를 사용해 적용하면 된다. 쿠버네티스는 이 선언된 내용을 기반으로 현재 상태를 바라는 상태로 자동 조정한다.
YAML 정의서
YAML은 가독성이 뛰어난 데이터 포맷으로, 구조화된 데이터를 계층적으로 표현하는 데 적합하다.
- 쿠버네티스에서는 Pod, Deployment, Service 등 다양한 리소스를 선언할 때 사용한다.
- 들여쓰기를 이용하여 계층 구조를 표현하며, JSON보다 사람이 읽기 쉽다.
예를 들어, 아래는 nginx 컨테이너가 실행되는 Pod를 선언하는 간단한 YAML 예제다.
apiVersion: v1
kind: Pod
metadata:
name: my-nginx
spec:
containers:
- name: nginx
image: nginx:latest
이러한 YAML형식의 리소스를 YAML 정의서라고 부른다.
네임스페이스
쿠버네티스에는 클러스터를 논리적으로 분리하는 네임스페이스라는 개념이 있다. 네임스페이스는 쿠버네티스 클러스터 내에서 리소스를 논리적으로 분리하는 단위로, 여러 워크로드를 독립적으로 관리할 수 있도록 한다. 각 네임스페이스는 자원 할당, 네트워크 정책, 접근 제어(RBAC) 등의 경계를 제공하여 멀티 테넌시 환경을 지원한다. 클러스터의 모든 리소스가 반드시 네임스페이스 내에 존재하는 것은 아니며, Node와 같은 일부 글로벌 리소스는 네임스페이스에 속하지 않는다.
🏢 네임스페이스 레벨 리소스 (Namespace-scoped Resources)
- 특정 네임스페이스 내에서만 존재하며, 네임스페이스를 통해 격리됨.
- 같은 리소스라도 다른 네임스페이스에 중복 생성 가능.
- 사용 예시: Pod, Deployment, Service, ConfigMap, Secret, Ingress, Role 등
🌍 클러스터 레벨 리소스 (Cluster-scoped Resources)
- 네임스페이스에 종속되지 않고 클러스터 전체에서 공유됨.
- 네임스페이스 구분 없이 단 하나만 존재할 수 있음.
- 사용 예시: Node, PersistentVolume(PV), ClusterRole, ClusterRoleBinding, Namespace, CustomResourceDefinition(CRD) 등
라벨(Label)과 셀렉터(Selector)
쿠버네티스에서 리소스를 효율적으로 관리하려면 특정 기준에 따라 그룹화할 필요가 있다. 이를 위해 **라벨(Label)**과 셀렉터(Selector) 개념을 사용한다. 라벨은 쿠버네티스 리소스에 부착할 수 있는 키-값(Key-Value) 형태의 메타데이터이다. 각 리소스에 고유한 의미를 부여할 수 있으며, 특정 리소스들을 논리적으로 그룹화하는 데 사용된다.
서비스 탐색
쿠버네티스 클러스터에서 통신하기위해 노드 위치와는 상관없이 어디서든 접근할 수 있는 서비스 끝점이 필요하다. 사용자(또는 Pod)은 서비스 끝점을 통해 다른 컨테이너와 통신할 수 있다. 쿠버네티스는 DNS기반 서비스 탐색을 지원하므로 보통의 상황에서는 따로 IP를 기억할 필요는 없다.
설정 관리
쿠버네티스는 컨테이너 실행에 필요한 환경 변수를 플랫폼 레벨에서 관리할 수 있게 해준다. 이에 따라 특정 서비스가 확장되더라도 기존과 같은 서버 설정을 외부에서 주입시켜줄 수 있다.
아키텍처
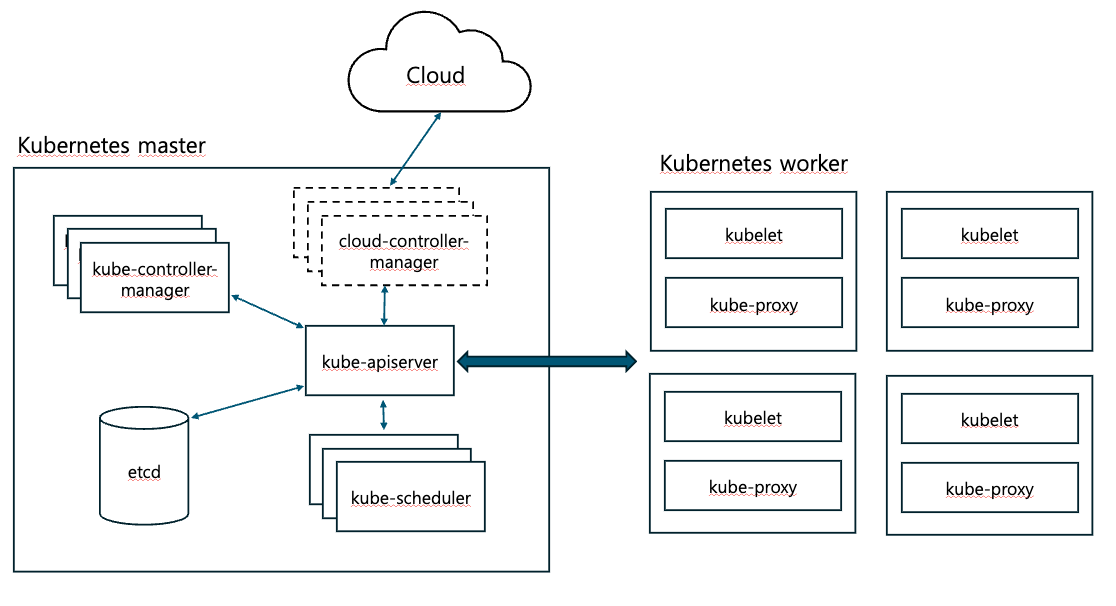
마스터 노드
마스터 노드에는 쿠버네티스 클러스터를 구성하는 핵심 컴포넌트들이 존재한다.
- kube-apiserver: 마스터로 전달되는 모든 요청을 받아들이는 REST API 서버
- etcd: 클러스터 내 모든 메타 정보를 저장하는 저장소
- kube-scheduler: 사용자의 요청에 따라 적절하게 컨테이너를 워커 노드에 배치하는 스케줄러
- kube-controller-manager: 현재 상태와 바라는 상태를 지속적으로 확인하여 이벤트에 따라 동작을 수행하는 컨트롤러
- cloud-controller-manager: 클라우드 플랫폼에 특화된 리소스를 제어하는 클라우드 컨트롤러
워커 노드
워커 노드에는 마스터로부터 명령을 전달받아 컨테이너를 실행시키는 노드 관리자(kubelet)과 컨테이너가 정상적으로 실행될 수 있도록 도와주는 네트워크 프록시와 실행 환경이 있다.
- kubelet: 마스터의 명령에 따라 컨테이너의 라이프사이클을 관리하는 노드 관리자
- kube-proxy: 컨테이너의 네트워킹을 책임지는 프록시
- containter runtime: 실제 컨테이너를 실행하는 컨테이너 실행 환경
쿠버네티스의 장점
- 실행 환경 고립화
컨테이너를 기반으로 애플리케이션을 배포하므로, 각 애플리케이션이 독립적인 환경에서 실행된다. 서로 다른 라이브러리와 의존성을 갖는 애플리케이션도 하나의 클러스터 내에서 문제없이 동작할 수 있다.
- 리소스 관리
쿠버네티스는 클러스터 내의 CPU, 메모리, 스토리지 등의 자원을 자동으로 할당 및 관리한다. 각 Pod 단위로 **리소스 요청(request)과 제한(limit)**을 설정하여, 특정 워크로드가 과도한 자원을 점유하는 것을 방지할 수 있다.
- 스케줄링
쿠버네티스는 사용자가 원하는 상태를 유지하도록 자동으로 Pod을 배치(scheduling)한다.
- 클러스터의 리소스 사용량, 노드 상태, 네트워크 연결성 등을 고려하여 최적의 노드에 Pod을 배치.
- taint, toleration, node affinity 같은 정책을 적용해 특정 노드에 특정 워크로드를 배정 가능.
- 프로세스 관리
Pod이 종료되거나 오류가 발생해도 쿠버네티스 컨트롤러가 자동으로 재시작한다. 이러한 자가 치유(Self-healing) 기능 덕분에 애플리케이션의 안정성이 증가한다.
- 통합 설정 관리
애플리케이션의 설정 값(Config)을 코드와 분리하여 관리할 수 있다.
- ConfigMap - 일반적인 설정 값을 저장하여 컨테이너가 참조할 수 있도록 함.
- Secret - API 키, 비밀번호 등의 민감한 정보를 안전하게 저장하고 관리.
- 손쉬운 장애 대응
쿠버네티스는 헬스 체크를 통해 비정상적인 컨테이너를 자동으로 감지하고 복구한다.
- Liveness Probe - 컨테이너가 정상적으로 실행 중인지 확인.
- Readiness Probe - 트래픽을 받을 준비가 되었는지 확인.
- Restart Policy - 컨테이너 장애 발생 시 자동 재시작 정책 설정.
- 자동 확장
애플리케이션의 부하에 따라 자동으로 Pod을 확장하거나 축소할 수 있다.
- Horizontal Pod Autoscaler (HPA) - CPU, 메모리 사용량을 기반으로 Pod 개수를 조정.
- Vertical Pod Autoscaler (VPA) - Pod이 사용하는 리소스 자체를 조정.
- Cluster Autoscaler - 클러스터 내 노드 수를 자동으로 확장하거나 축소.
- 하이브리드 클라우드 운영
쿠버네티스는 온프레미스, 퍼블릭 클라우드(AWS, GCP, Azure) 환경에서 동일한 방식으로 운영할 수 있다. 멀티 클러스터 또는 하이브리드 클라우드 환경에서도 일관된 애플리케이션 배포 및 관리가 가능하다.
- 자가 치유 (Self-healing)
- 쿠버네티스는 오류가 발생한 Pod을 자동으로 감지하고 대체한다.
- 비정상적인 컨테이너를 재시작하거나, 일정 시간이 지나도록 응답이 없으면 새로운 Pod을 생성.
- 노드 장애가 발생하면 해당 Pod을 정상적인 노드로 재배치하여 서비스 지속성을 보장.
- 데이터 스토리지 관리
쿠버네티스는 다양한 **스토리지 백엔드(Local, NFS, Cloud Storage, Ceph, GlusterFS 등)**를 지원한다.
- PersistentVolume (PV) - 클러스터 내에서 지속적인 데이터 저장 공간을 제공.
- PersistentVolumeClaim (PVC) - 애플리케이션이 스토리지를 요청할 때 사용하는 리소스.
- StorageClass - 동적 볼륨 프로비저닝(Dynamic Provisioning)을 통해 자동으로 스토리지를 할당.
- 배포 자동화
쿠버네티스는 Rolling Update, Canary, Blue-Green Deployment 같은 다양한 배포 전략을 지원한다.
- Rolling Update - 기존 Pod을 점진적으로 교체하여 다운타임 없이 업데이트.
- Canary Deployment - 일부 트래픽만 새로운 버전으로 전환하여 점진적 배포.
- Blue-Green Deployment - 기존 버전과 새 버전을 동시에 운영하며 안전한 전환을 지원.