Chap 6. 쿠버네티스 네트워킹

Service
쿠버네티스에는 Pod 자체에도 IP가 부여된다. curl 명령을 통해 Pod IP로 호출을 하면 정상적으로 결과를 반환한다. 그렇다면 왜 Service라는 리소스가 필요한걸까?
위와 같이 Pod의 IP로 바로 연결이 가능한데도 말이다.
불안정한 Pod vs. 안정적인 Service
쿠버네티스에서는 Pod 리소스를 불안정한 자원으로 여긴다. Pod는 필요한 경우 쉽게 생성하였다가 사용이 끝나면 쉽게 삭제될 수 있는 만큼, Pod에 할당된 IP는 불안정한 엔드포인트로 간주된다.
이 때문에, 사용자가 Pod의 엔드포인트를 통해 애플리케이션과 소통을 시도한다면, Pod가 변경되거나 내려가거나 새로 생성될때마다 사용자는 바뀐 IP를 추적해야만 할 것이다. 이 문제를 해결하고자 Pod의 생명주기와 관계없이 안정적인 엔드포인트를 제공하는 Service라는 리소스가 등장하게 되었다.
Service는 Pod의 앞단에 위치하며 Service로 들어오는 트래픽을 Pod로 전달하는 리버스 프록시 역할을 수행한다. Service 리소스 덕분에 Pod의 IP가 변경되더라도 사용자입장에서는 동일한 IP로 서비스에 접근할 수 있어서 어떤 Pod이 존재하는지, 몇개의 Pod이 존재하는지에 관계 없이 트래픽 전달이 가능하여 안정성 및 가용성을 높힐 수 있다.
서비스 디스커버리
Kubernetes의 Service 리소스는 안정적인 IP를 제공할 뿐만 아니라, 서비스 탐색 기능을 수행하는 DNS 기반 엔드포인트도 제공한다.
클러스터 내에서 실행 중인 Pod는 서비스명.네임스페이스.svc.cluster.local 형식의 DNS 이름을 사용하여 다른 서비스와 통신할 수 있다.
예를 들어, my-service가 dev 네임스페이스에서 실행 중이라면 다음과 같은 DNS 주소로 접근할 수 있다.
my-service.dev.svc.cluster.local
네임스페이스에 따른 DNS 차이점
-
같은 네임스페이스 내에서는 서비스 이름만 사용해도 자동으로 해당 서비스를 찾을 수 있다.
curl http://my-service:8080Kubernetes DNS가
my-service.dev.svc.cluster.local을 자동으로 찾아준다. -
다른 네임스페이스의 서비스에 접근할 경우, 전체 FQDN을 사용해야 한다.
curl http://my-service.prod.svc.cluster.local:8080네임스페이스가 다르면 Kubernetes가 자동으로 같은 네임스페이스에서 찾지 않기 때문에 전체 도메인을 지정해야 한다.
Service 첫 만남
다음과 같이 첫 Service 리소스를 생성할 수 있다.
apiVersion: v1
kind: Service
metadata:
name: myservice
labels:
hello: world
spec:
ports:
- protocol: TCP
port: 8080
targetPort: 80
selector:
run: mynginx
apiVersion: 사용할 API 그룹과 버전을 정의한다. 여기서는v1을 사용하여 기본 Kubernetes API를 활용한다.kind: 생성할 리소스의 종류를 지정한다. 여기서는Service를 정의한다.metadata: Service의 메타데이터 정보를 포함한다.name: Service의 이름을 지정한다. 클러스터 내에서 유일해야 한다.labels: 해당 Service에 부여하는 라벨로, 리소스를 식별하는 데 사용된다.
spec: Service의 동작을 정의하는 영역이다.ports: Service가 노출할 포트를 정의한다.protocol: 사용할 프로토콜을 지정한다. (기본값:TCP)port: 클러스터 내부에서 Service가 노출하는 포트 번호.targetPort: Service가 트래픽을 전달할 Pod 내부의 포트 번호.
selector: 이 Service가 트래픽을 전달할 대상 Pod을 선택하는 라벨 셀렉터이다.run: mynginx라벨이 지정된 Pod과 연결된다.
위 설정을 통해 myservice라는 이름의 Service가 생성되며, run: mynginx 라벨이 있는 Pod에 8080 포트로 트래픽을 받아서 80 포트로 전달한다.
LabelSelector를 이용해서 Pod을 선택하는 이유
Kubernetes의 Service는 특정 Pod의 IP가 아니라, LabelSelector를 기반으로 Pod을 선택한다.
이는 느슨한 연결(loose coupling) 을 유지하기 위한 핵심 설계 원칙이다.
Pod의 동적 생성 및 삭제 대응
Pod는 필요에 따라 생성되고 삭제될 수 있기 때문에, 특정 Pod의 IP에 의존하는 방식은 불안정하다.
LabelSelector를 사용하면 Pod이 새로 생성될 때도 자동으로 Service에 포함될 수 있다.애플리케이션 확장성
만약 애플리케이션이 스케일 아웃되어 더 많은 Pod이 생성된다면,LabelSelector를 통해 자동으로 트래픽이 새로운 Pod으로 분산된다.
반대로, 부하가 줄어들어 일부 Pod이 삭제되더라도 Service 설정을 변경할 필요 없이 나머지 Pod이 트래픽을 처리한다.독립적인 배포 및 운영 가능
개발자가 새로운 버전의 애플리케이션을 배포할 때, 기존 Pod을 삭제하고 새로운 Pod을 생성하는 방식(롤링 업데이트)이 일반적이다.
이때, 새로운 Pod이 기존과 동일한 라벨을 가지면 자동으로 Service의 대상이 되어 연결이 유지된다.유지보수 및 관리 용이성
특정 Pod의 IP를 사용하면 관리가 복잡해지고 변경 사항을 적용하기 어렵다.
하지만LabelSelector를 이용하면 라벨만으로 특정 Pod 그룹을 지정할 수 있어 유지보수가 훨씬 쉬워진다.
이러한 이유로 Kubernetes는 서비스와 Pod을 직접 연결하는 것이 아니라, 라벨을 기반으로 연결하는 구조를 채택하고 있다.
이를 통해 애플리케이션의 유연성과 확장성을 보장할 수 있다.
클러스터 DNS 서버
Service 이름을 도메인 주소로 사용이 가능한 이유는 쿠버네티스에서 제공하는 DNS 서버가 있기 떄문이다.
리눅스 시스템에서 DNS 서버 설정을 담당하는 /etc/resolv.conf 파일을 확인해보자

보이는 바와 같이 kube-dns라는 서비스가 네임서버의 트래픽을 받고 있다는 것을 확인 가능하다.

해당 서비스의 라벨을 확인하면 k8s-app: kube-dns 가 보이는데, 이 라벨로 Pod을 조회하면 coredns 파드가 나온다.
이 Pod들이 실제 네임서버 트래픽을 받아서 처리하는 주체들이다.
💡모든 Pod들은 클러스터 내,외부 DNS질의를 coredns를 통해 수행한다. 이러한 이유로 k8s는 자체적인 도메인 네임 시스템을 가진다.
Service 종류
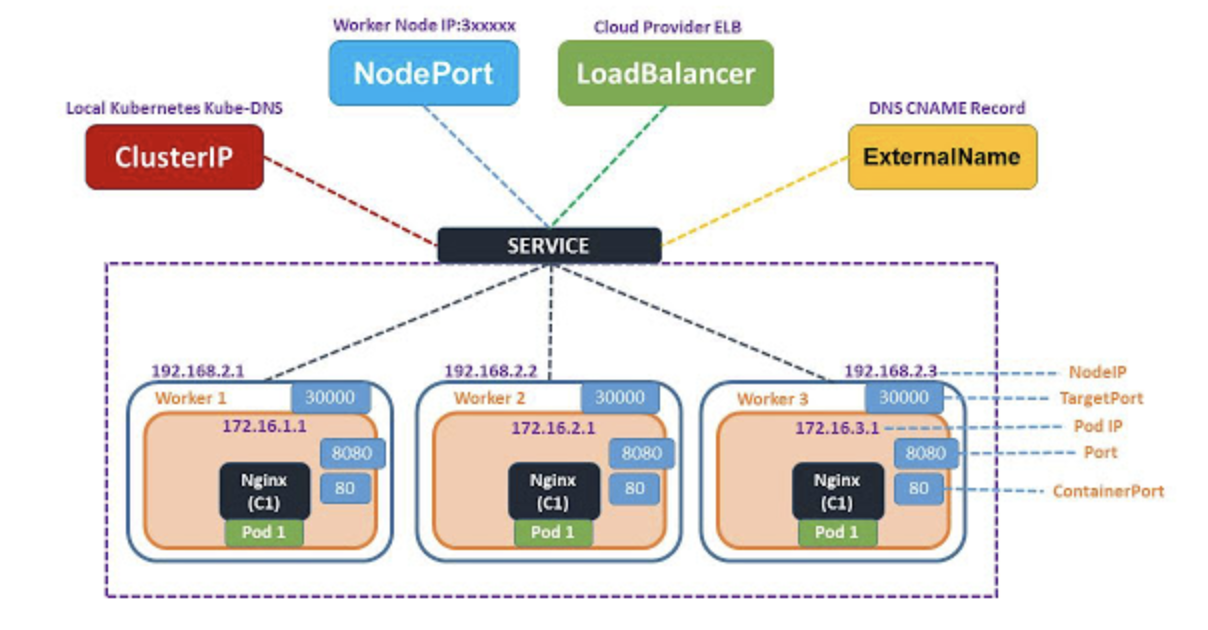
서비스 리소스에는 총 4가지 타입이 있다. 클러스터 내에서 동작하는 가장 기본적인 타입부터 외부 트래픽을 받을 수 있는 로드밸런서 타입까지 다양한 타입들을 하나씩 살펴 보자.
1. ClusterIP
ClusterIP는 Service 리소스의 가장 기본이 되는 타입으로, 별 다른 타입 지정이 없다면 ClusterIP로 설정된다. 클러스터 외부에서의 접근이 불가능하며, 클러스터 내부의 Pod들만 접근이 가능하다.
--expose, --port 옵션을 통해서 Imperative Command로 만들 수도 있고, 아래와 같이 yaml 파일로 정의할 수도 있다.
apiVersion: v1
kind: Service
metadata:
name: cluster-ip
spec:
ports:
- port: 8080
protocol: TCP
targetPort: 80
selector:
run: cluster-ip
type: ClusterIP #생략가능
---
apiVersion: v1
kind: Pod
metadata:
labels:
run: cluster-ip
name: cluster-ip
spec:
containers:
- image: nginx
name: cluster-ip
ports:
- containerPort: 80
dnsPolicy: ClusterFirst
restartPolicy: Always
위에서는 타입을 ClusterIP라고 명시했지만, 따로 명시하지 않아도 자동으로 ClusterIP로 지정된다.
2. NodePort
외부 트래픽을 클러스터 내로 전달하고 싶다면 NodePort타입을 사용할 수 있다. 이는 도커 컨테이너 포트 매핑과 비슷하게 로컬 호스트의 특정 포트(노드의 포트)를 서비스의 특정 포트와 연결시켜 외부 트래픽을 Service까지 전달할 수 있다.
(물론 노드의 방화벽에서 포트를 열어줘야한다)
apiVersion: v1
kind: Service
metadata:
name: node-port
spec:
ports:
- port: 8080
protocol: TCP
targetPort: 80
selector:
run: node-port
type: NodePort
---
apiVersion: v1
kind: Pod
metadata:
labels:
run: node-port
name: node-port
spec:
containers:
- image: nginx
name: nginx
ports:
- containerPort: 80
🤔 책에서는 Sercvice의 selector를
mynginx라고 지정했는데... 그러면 Pod를 프록시하지 못하게된다...
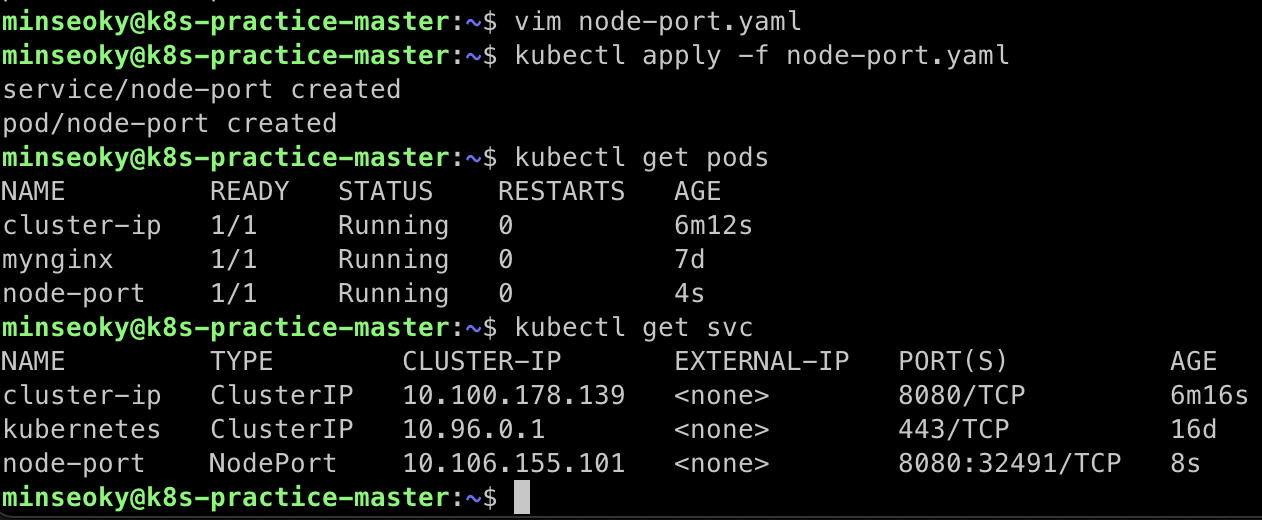
서비스 포트인 8080과 외부 포트인 32491과 연결된 것을 확인할 수 있다.
이를 통해 노드의 외부 포트인 32491로 연결을 시도하면, 노드(32491) -> 서비스(8080) -> 포드(80) 으로 요청이 전달될 것을 알 수 있다.
💡 쿠버네티스는 클러스터 시스템이므로 어떤 노드에서든 32491포트로 접근하면 서비스에 접근할 수 있다. 이는
kube-proxy덕분으로, 리눅스 커널의 netfilter를 이용해서 커널 레벨에서 트래픽을 가로채 다른곳으로 라우팅해주는 역할을 한다.
3. LoadBalancer
NodePort는 외부 트래픽을 내부로 전달하는 좋은 방법이지만, 노드별로 트래픽을 분산하기 위해서는 LoadBalancer 타입을 사용해야한다.
LoadBalancer타입이 가지는 장점은 다음과 같다.
- 보안성:
호스트 서버의 노트포트 대역(30000-32767 / 변경 가능)을 외부에 공개할 필요 없이 LB만 외부 네트워크에 위치시켜 엔트포인트로 사용하여 네트워크 보안성을 높힐 수 있다. - 편의성:
로드 밸런서가 클러스터 앞단에 위치하면 사용자가 각각의 서버 IP를 알 필요 없이 로드밸런서의 IP(혹은 도메인 주소)만 가지고 요청을 보낼 수 있다.
즉, ClusterIP가 Pod 레벨에서의 안정적인 엔드포인트를 제공했다면, LoadBalancer는 Node 레벨에서의 안정적인 엔드포인트를 제공한다.
보통 로드밸런서는 클라우드 플랫폼에서 제공하는 것을 사용한다(ex: AWS ELB).
💡 온프레미스 환경에서는 MetalLB와 같은 온프레미스 전용 로드밸런서를 사용해야 한다. MetalLB는 L2, L3 기반의 로드밸런싱을 제공하므로 일반적으로 클라우드 플랫폼에서 제공하는 L4, L7 기반 로드밸런싱보다 속도가 빠르다.
번외로 클라우드 플랫폼에서 L2, L3 기반 로드밸런싱을 제공하지 않는 이유는 모든 네트워크가 SDN(Software Defined Network)로 구성되어있어 하위 레이어의 정보를 숨기기 때문이다.
apiVersion: v1
kind: Service
metadata:
name: load-bal
spec:
ports:
- port: 8080
protocol: TCP
targetPort: 80
selector:
run: load-bal
type: LoadBalancer
---
apiVersion: v1
kind: Pod
metadata:
labels:
run: load-bal
name: load-bal
spec:
containers:
- image: nginx
name: nginx
ports:
- containerPort: 80
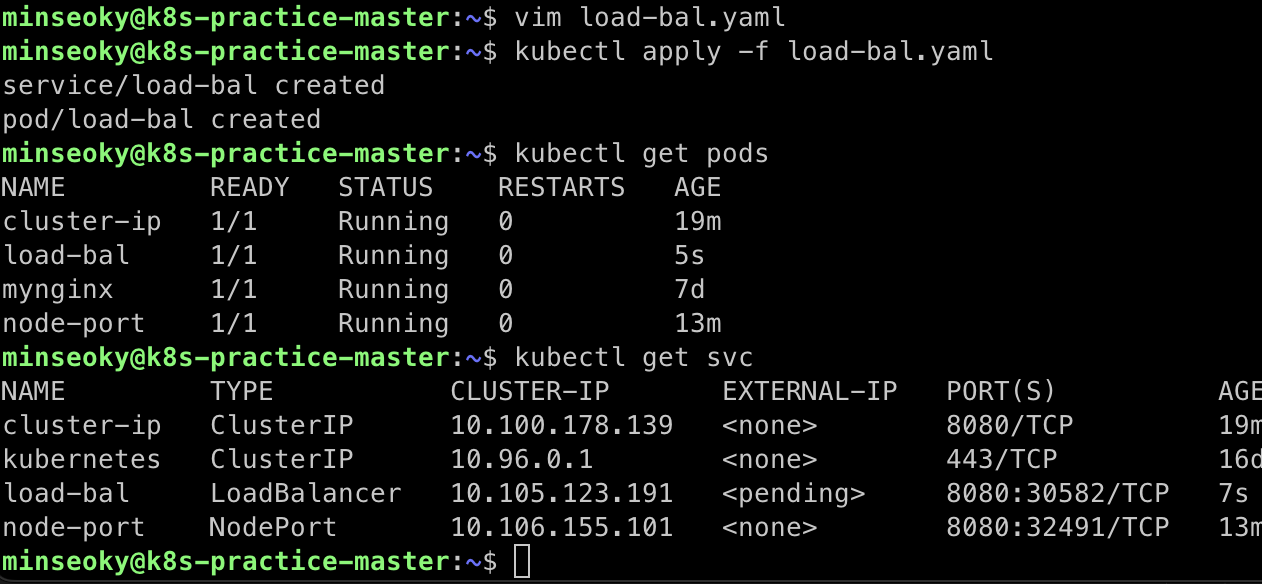
위에서 보이듯, 로드밸런서 서비스를 생성했지만 EXTERNAL-IP가 할당되지 않고 <pending>상태인것을 관찰할 수 있다. 이는 실제 외부 로드밸런서가 없기 때문으로,
클라우드 플랫폼을 사용중인것도 아니고, MetalLB같은 온프레미스 외부 로드밸런서 툴을 사용하는것도 아니라서 그런것이다.
MetalLB를 사용한 예는 다음과 같다.
위와 같이 MetalLB가 설치되어있으면,
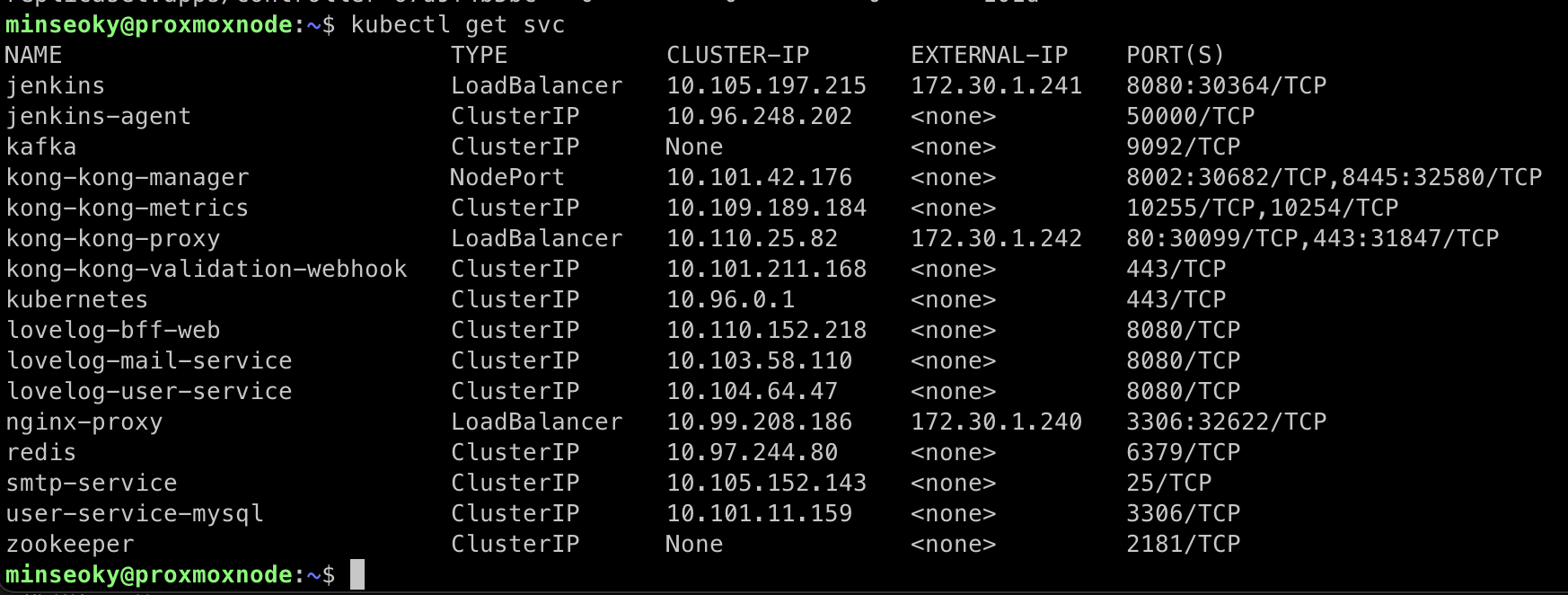
LoadBalancer타입의 서비스들에 정상적으로 EXTERNAL-IP가 할당된 것을 관찰할 수 있다.
4, ExternalName
ExternalName은 외부 DNS주소에 클러스터 내부에서 사용할 새로운 alias를 만든다.
apiVersion: v1
kind: Service
metadata:
name: google-svc # Alias
spec:
type: ExternalName
externalName: google.com # 외부 DNS
위와 같이 서비스를 만들면 클러스터 내부에서 google-svc로 google.com에 접근이 가능해진다.
외부 서비스와 쿠버네티스 클러스터 네트워킹 기능을 연결하고 싶을 때 사용한다.
네트워크 모델
쿠버네티스 네트워크 모델은 다음과 같은 특징을 가진다.
- 각 Node간 NAT 없이 통신이 가능해야 한다.
- 각 Pod간 NAT 없이 통신이 가능해야 한다.
- Node와 Pod간 NAT 없이 통신이 가능해야 한다.
- 각 Pod는 고유의 IP를 부여받는다.
- 각 Pod IP는 네트워크 제공자(네트워크 플러그인: Container Network Interface)를 통해 할당받는다. (ISP를 말하는게 아님)
- Pod IP는 클러스터 내부 어디서든 접근이 가능해야 한다.
쿠버네티스 네트워크 모델은 NAT에 대한 종속성을 탈피하려고 한다.
💡 쿠버네티스의 전신인 Borg라는 구글 내부 클러스터 시스템에서는 NAT 통신을 사용했는데, 모든 컨테이너들이 동일한 IP를 갖게되어 Port로 구분을 했다. 그에 따라 동일한 Port를 사용하는 경우 포트 충돌이 일어나게 되어 관리자의 책임이 늘어났다. 그에 따라 쿠버네티스에서는 반면교사 삼아 Pod과 Node의 네트워크 환경을 서로 분리하게 되었다고한다.
⚠️ 클러스터 외부 네트워크에서 바라보는 쿠버네티스 클러스터 자체는 NAT이 맞다. 여기서 말하는 NAT을 지양한다는 이야기는 클러스터 내부에 국한된다.