쿠버네티스

쿠버네티스란?
컨테이너는 애플리케이션을 포장하고 실행하는 좋은 방법이다. 프로덕션 환경에서는 애플리케이션을 실행하는 컨테이너를 관리하고 가동 중지 시간이 없는지 확인해야 한다. 예를 들어 컨테이너가 다운되면 다른 컨테이너를 다시 시작해야 한다. 이 문제를 시스템에 의해 처리한다면 더 쉽지 않을까?
그것이 쿠버네티스가 필요한 이유이다! 쿠버네티스는 분산 시스템을 탄력적으로 실행하기 위한 프레임 워크를 제공한다. 애플리케이션의 확장과 장애 조치를 처리하고, 배포 패턴 등을 제공한다. 예를 들어, 쿠버네티스는 시스템의 카나리아 배포를 쉽게 관리할 수 있다.
쿠버네티스는 다음을 제공한다.
- 서비스 디스커버리와 로드 밸런싱: 쿠버네티스는 DNS 이름을 사용하거나 자체 IP 주소를 사용하여 컨테이너를 노출할 수 있다. 컨테이너에 대한 트래픽이 많으면, 쿠버네티스는 네트워크 트래픽을 로드밸런싱하고 배포하여 배포가 안정적으로 이루어질 수 있다.
- 스토리지 오케스트레이션: 쿠버네티스를 사용하면 로컬 저장소, 공용 클라우드 공급자 등과 같이 원하는 저장소 시스템을 자동으로 탑재할 수 있다
- 자동화된 롤아웃과 롤백: 쿠버네티스를 사용하여 배포된 컨테이너의 원하는 상태를 서술할 수 있으며 현재 상태를 원하는 상태로 설정한 속도에 따라 변경할 수 있다. 예를 들어 쿠버네티스를 자동화해서 배포용 새 컨테이너를 만들고, 기존 컨테이너를 제거하고, 모든 리소스를 새 컨테이너에 적용할 수 있다.
- 자동화된 빈 패킹(bin packing): 컨테이너화된 작업을 실행하는데 사용할 수 있는 쿠버네티스 클러스터 노드를 제공한다. 각 컨테이너가 필요로 하는 CPU와 메모리(RAM)를 쿠버네티스에게 지시한다. 쿠버네티스는 컨테이너를 노드에 맞추어서 리소스를 가장 잘 사용할 수 있도록 해준다.
- 자동화된 복구(self-healing): 쿠버네티스는 실패한 컨테이너를 다시 시작하고, 컨테이너를 교체하며, '사용자 정의 상태 검사'에 응답하지 않는 컨테이너를 죽이고, 서비스 준비가 끝날 때까지 그러한 과정을 클라이언트에 보여주지 않는다.
- 시크릿과 구성 관리: 쿠버네티스를 사용하면 암호, OAuth 토큰 및 SSH 키와 같은 중요한 정보를 저장하고 관리할 수 있다. 컨테이너 이미지를 재구성하지 않고 스택 구성에 시크릿을 노출하지 않고도 시크릿 및 애플리케이션 구성을 배포 및 업데이트할 수 있다.
쿠버네티스가 아닌 것
쿠버네티스는 전통적인, 모든 것이 포함된 Platform as a Service(PaaS)가 아니다. 쿠버네티스는 하드웨어 수준보다는 컨테이너 수준에서 운영되기 때문에, PaaS가 일반적으로 제공하는 배포, 스케일링, 로드 밸런싱과 같은 기능을 제공하며, 사용자가 로깅, 모니터링 및 알림 솔루션을 통합할 수 있다. 하지만, 쿠버네티스는 모놀리식(monolithic)이 아니어서, 이런 기본 솔루션이 선택적이며 추가나 제거가 용이하다. 쿠버네티스는 개발자 플랫폼을 만드는 구성 요소를 제공하지만, 필요한 경우 사용자의 선택권과 유연성을 지켜준다.
쿠버네티스는:
- 지원하는 애플리케이션의 유형을 제약하지 않는다. 쿠버네티스는 상태 유지가 필요 없는(stateless) 워크로드, 상태 유지가 필요한(stateful) 워크로드, 데이터 처리를 위한 워크로드를 포함해서 극단적으로 다양한 워크로드를 지원하는 것을 목표로 한다. 애플리케이션이 컨테이너에서 구동될 수 있다면, 쿠버네티스에서도 잘 동작할 것이다.
- 소스 코드를 배포하지 않으며 애플리케이션을 빌드하지 않는다. 지속적인 통합과 전달과 배포, 곧 CI/CD 워크플로우는 조직 문화와 취향에 따를 뿐만 아니라 기술적인 요구사항으로 결정된다.
- 애플리케이션 레벨의 서비스를 제공하지 않는다. 애플리케이션 레벨의 서비스에는 미들웨어(예, 메시지 버스), 데이터 처리 프레임워크(예, Spark), 데이터베이스(예, MySQL), 캐시 또는 클러스터 스토리지 시스템(예, Ceph) 등이 있다. 이런 컴포넌트는 쿠버네티스 상에서 구동될 수 있고, 쿠버네티스 상에서 구동 중인 애플리케이션이 Open Service Broker와 같은 이식 가능한 메커니즘을 통해 접근할 수도 있다.
- 로깅, 모니터링 또는 경보 솔루션을 포함하지 않는다. 개념 증명을 위한 일부 통합이나, 메트릭을 수집하고 노출하는 메커니즘을 제공한다.
- 기본 설정 언어/시스템(예, Jsonnet)을 제공하거나 요구하지 않는다. 선언적 명세의 임의적인 형식을 목적으로 하는 선언적 API를 제공한다.
- 포괄적인 머신 설정, 유지보수, 관리, 자동 복구 시스템을 제공하거나 채택하지 않는다.
- 추가로, 쿠버네티스는 단순한 오케스트레이션 시스템이 아니다. 사실, 쿠버네티스는 오케스트레이션의 필요성을 없애준다. 오케스트레이션의 기술적인 정의는 A를 먼저 한 다음, B를 하고, C를 하는 것과 같이 정의된 워크플로우를 수행하는 것이다. 반면에, 쿠버네티스는 독립적이고 조합 가능한 제어 프로세스들로 구성되어 있다. 이 프로세스는 지속적으로 현재 상태를 입력받은 의도한 상태로 나아가도록 한다. A에서 C로 어떻게 갔는지는 상관이 없다. 중앙화된 제어도 필요치 않다. 이로써 시스템이 보다 더 사용하기 쉬워지고, 강력해지며, 견고하고, 회복력을 갖추게 되며, 확장 가능해진다.
컨테이너 오케스트레이션
⭐️ "컨테이너화 된 애플리케이션에 대한 자동화된 설정, 관리 및 제어 체계"

마이크로서비스 아키텍처(MSA; Microservice Architecture)에서는 프로젝트에 포함된 세부 기능들이 작은 서비스 단위로 분리되어 구축된다. 이 각각의 서비스를 구현할 때 컨테이너 기술이 흔하게 이용된다. 한정된 적은 양의 컨테이너는 개별 관리자가 손수 관리할 수도 있겠지만, 대규모의 상용 프로젝트 환경에서 수많은 컨테이너를 이런 식으로 제어하는 것은 불가능하다. 동시에 수백, 수천 개의 컨테이너를 배포하고 관리해야 하는 상황이라면 아래의 4가지 이슈에 대한 해답을 반드시 찾아야 한다.
- 배포 관리 : 어떤 컨테이너를 어느 호스트에 배치하여 구동시킬 것인가? 각 호스트가 가진 한정된 리소스에 맞춰 어떻게 최적의 스케줄링을 구현할 것인가? 어떻게 하면 이러한 배포 상태를 최소한의 노력으로 유지 관리할 수 있을 것인가?
- 제어 및 모니터링 : 구동 중인 각 컨테이너들의 상태를 어떻게 추적하고 관리할 것인가?
- 스케일링 : 수시로 변화하는 운영 상황과 사용량 규모에 어떻게 대응할 것인가?
- 네트워킹 : 이렇게 운영되는 인스턴스 및 컨테이너들을 어떻게 상호 연결할 것인가?
위의 4가지 이슈를 해결하기 위해 나타난 개념이 바로 컨테이너 오케스트레이션(Container Orchestration) 이다. 관현악 연주에서 각기 다른 파트를 맡은 연주자들이 하나의 연주를 위해 동시에 조화를 이루듯이, 온라인 인프라 환경에서 대규모의 컨테이너들이 안정적으로 운영될 수 있도록 관리의 복잡성을 줄여주고 이를 자동화하는 것이다. 쿠버네티스는 이러한 컨테이너 오케스트레이션 개념을 구현한 도구들 중 하나다.
쿠버네티스의 핵심 설계 사상 5가지
그렇다면 대규모 컨테이너 배포 및 관리를 위해 쿠버네티스가 제공하는 고유의 특징적인 설계 요소는 어떤 것들이 있을까? 크게 다섯 가지로 압축하여 보자면 다음과 같다.
1. 선언적 구성 기반의 배포 환경
쿠버네티스에서는 동작을 지시하는 개념 (예: 레플리카를 5개 만들어라) 보다는 원하는 상태를 선언하는 개념 (예: 내 호스트의 레플리카를 항상 5개로 유지하라) 을 주로 사용한다. 쿠버네티스는 원하는 상태(Desired state)와 현재의 상태(Current state)가 상호 일치하는지를 지속적으로 체크하고 업데이트한다. 따라서 내게 필요한 요소에 대해 원하는 상태를 설정하는 것만으로도 호스트의 리소스 현황에 맞춰 최적의 배치로 배포되거나 변경된다. 만약 특정 요소에 문제가 생겼을 경우, 쿠버네티스는 해당 요소가 원하는 상태로 다시 복구될 수 있도록 필요한 조치를 자동으로 취한다.
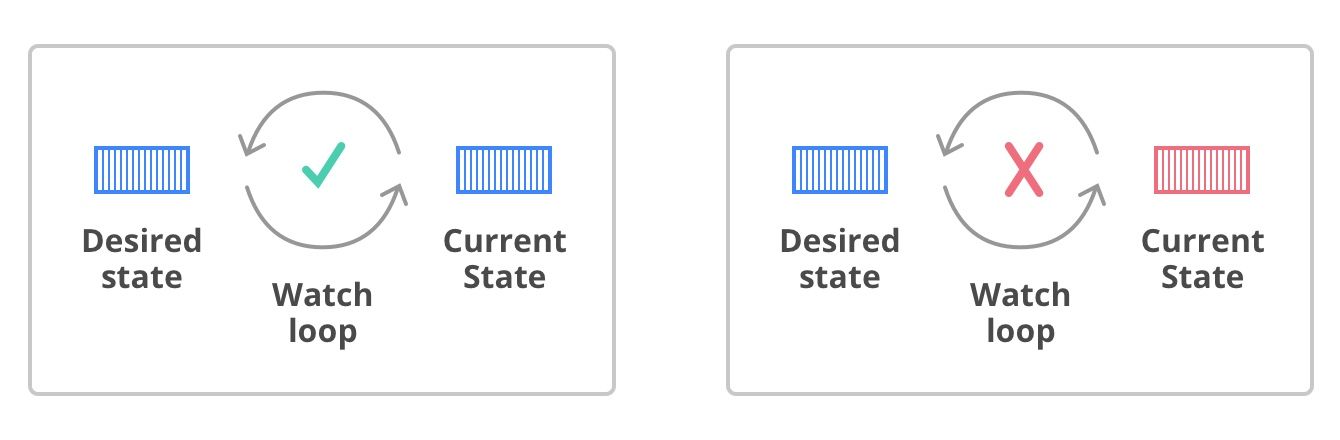
쿠버네티스는 원하는 상태가 현재의 상태로 될 수 있도록 계속해서 모니터링하고 관리한다. (이미지 출처 : Leverage)
2. 기능 단위의 분산
쿠버네티스에서는 각각의 기능들이 개별적인 구성 요소로서 독립적으로 분산되어 있다. 실제로 노드(Node), 레플리카셋(ReplicaSet), 디플로이먼트(Deployment), 네임스페이스(Namespace) 등 클러스터를 구성하는 주요 요소들이 모두 컨트롤러(Controller)로서 구성되어 있으며, 이들은 Kube Controller Manager안에 패키징 되어 있다.
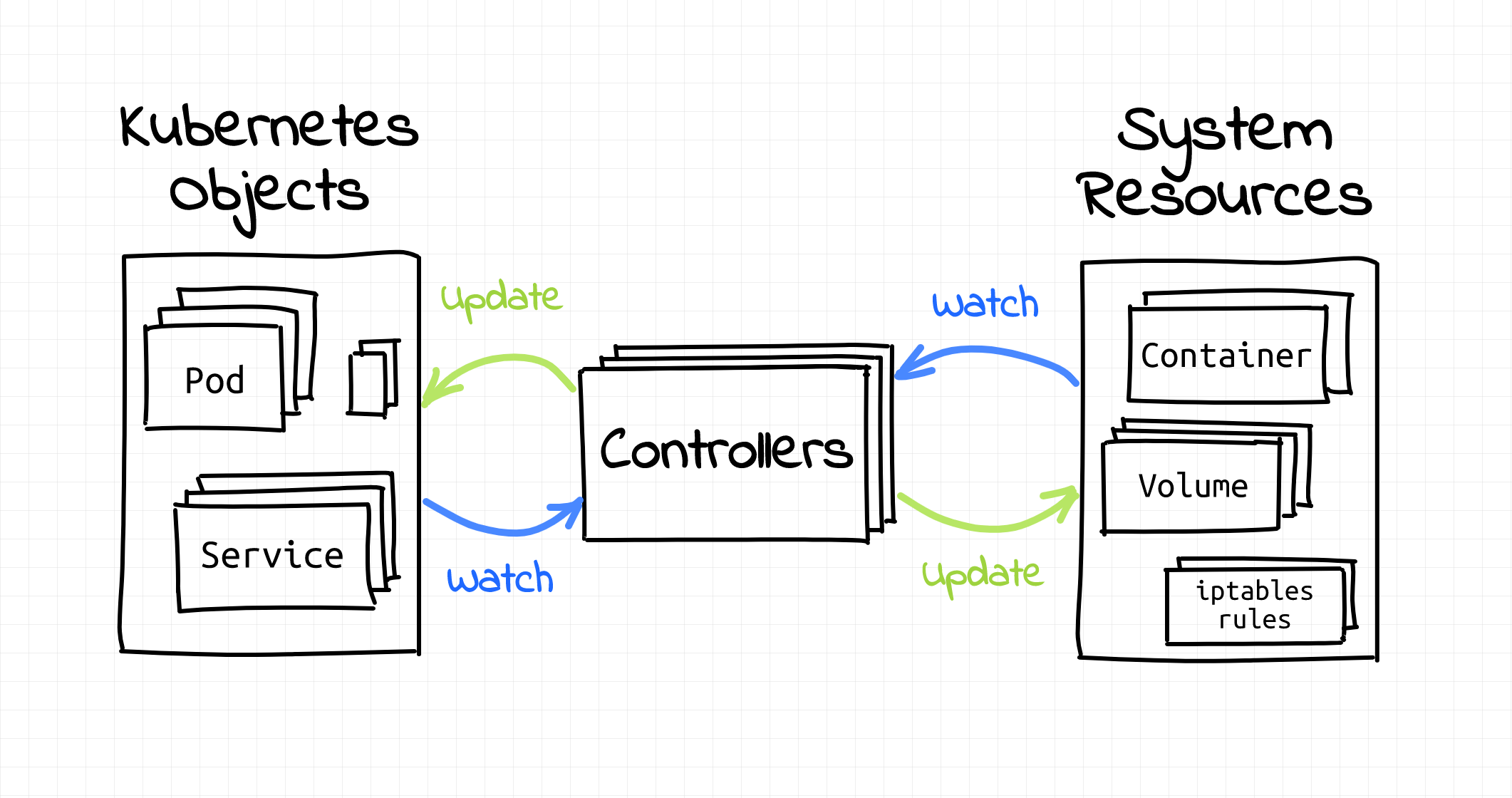
쿠버네티스는 내부 요소들의 상태 관리를 위해 컨트롤러를 이용한다. (이미지 출처: iximiuz.com)
3. 클러스터 단위 중앙 제어
쿠버네티스에서는 전체 물리 리소스를 클러스터 단위로 추상화하여 관리한다. 클러스터 내부에는 클러스터의 구성 요소들에 대해 제어 권한을 가진 컨트롤 플레인(Control Plane) 역할의 마스터 노드(Master Node)를 두게 되며, 관리자는 이 마스터 노드를 이용하여 클러스터 전체를 제어한다.
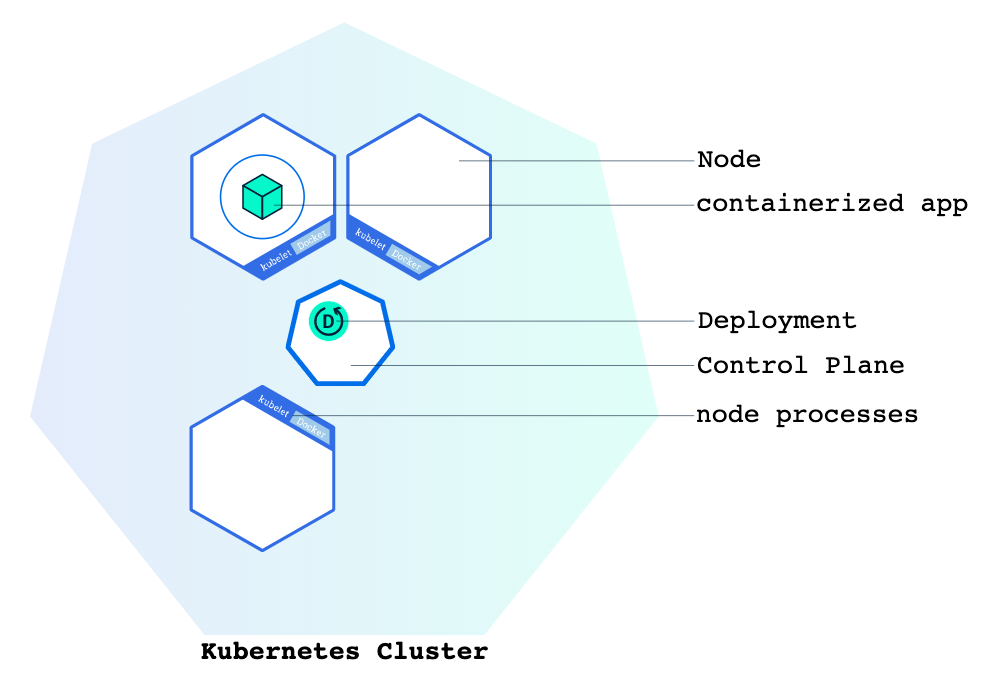
쿠버네티스는 클러스터 단위로 중앙 제어되는 구조를 가진다. (이미지 출처: Kubernetes Documentation)
4. 동적 그룹화
쿠버네티스의 구성 요소들에는 쿼리 가능한 레이블(Label)과 메타데이터용 어노테이션(Annotation)에 임의로 키-값 쌍을 삽입할 수 있다. 관리자는 selector를 이용해서 레이블 기준으로 구성 요소들을 유연하게 관리할 수 있고, 어노테이션에 기재된 내용을 참고하여 해당 요소의 특징적인 내역을 추적할 수 있다.
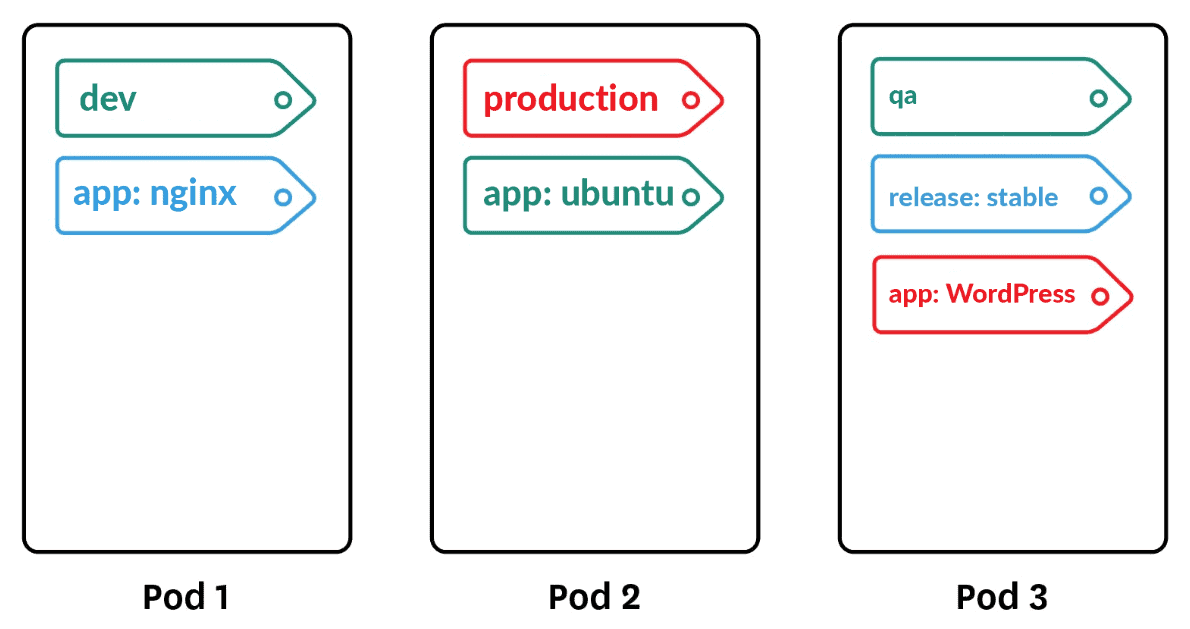
레이블(Label)을 이용하면 구성 요소를 유연하게 그룹화할 수 있다. (이미지 출처 : K21Academy)
5. API 기반 상호작용
쿠버네티스의 구성 요소들은 오직 Kubernetes API server(kube-apiserver)를 통해서만 상호 접근이 가능한 구조를 가진다. 마스터 노드에서 kubectl을 거쳐 실행되는 모든 명령은 이 API 서버를 거쳐 수행되며, 컨트롤 플레인(Control Plane)에 포함된 클러스터 제어 요소나 워커 노드(Worker Node)에 포함된 kubelet, 프록시 역시 API 서버를 항상 바라보게 되어 있다.
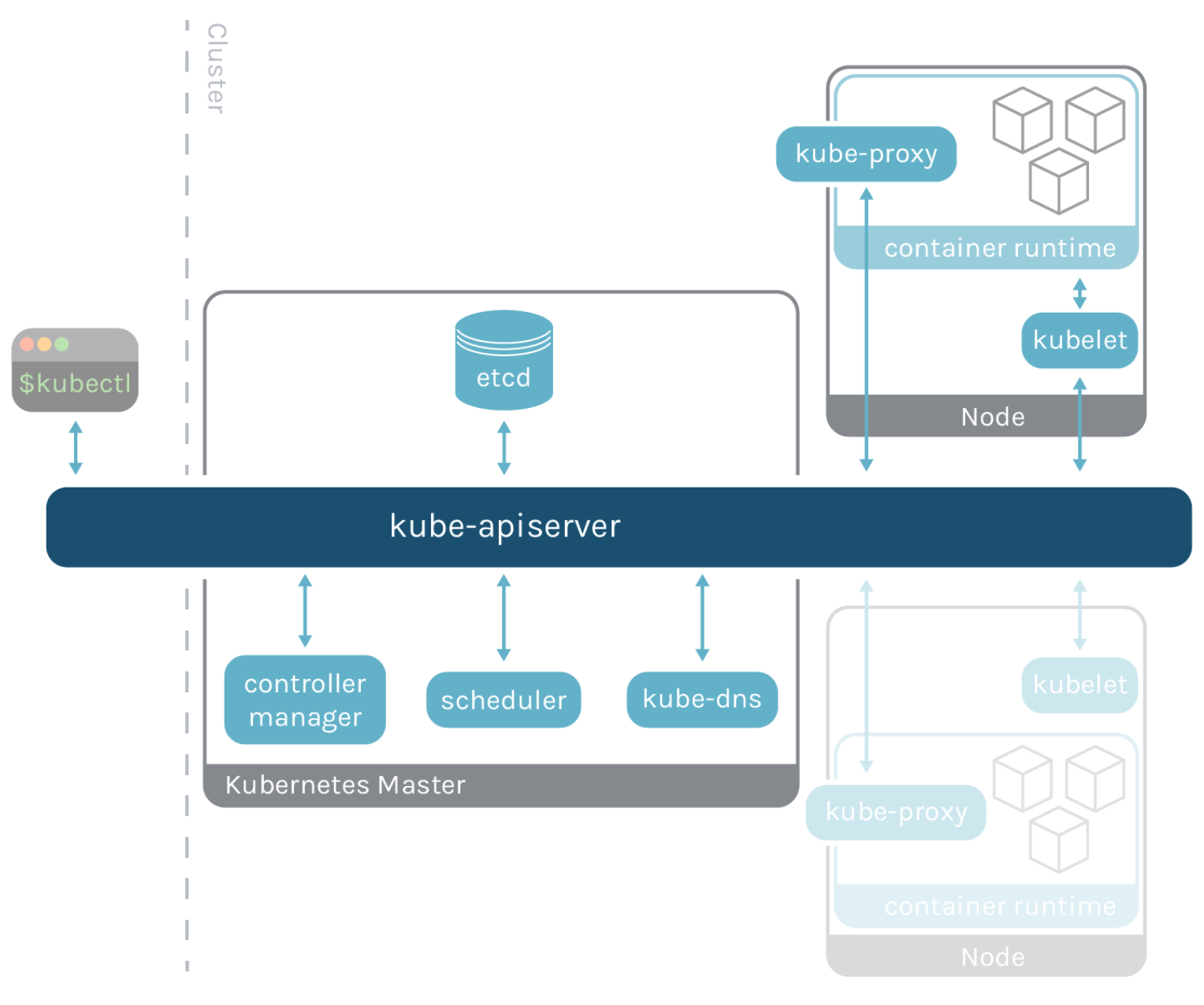
쿠버네티스의 많은 핵심 요소들이 API 서버를 바라보는 구조로 되어있다. (이미지 출처: Sysdig)