엘라스틱서치 기본 동작 및 구조

🔍 엘라스틱서치 스터디 시리즈
엘라스틱 서치 기본 동작
엘라스틱 서치는 REST API 기반 서치 엔진으로, 데이터의 수정/삭제 작업은 모두 Json을 기반으로 한 REST API를 통해 진행할 수 있습니다.
1. 문서 색인
_id를 지정하여 문서를 색인할 수 있습니다.
PUT [인덱스이름]/_doc/[_id값]
{
[문서내용]
}
예시 요청
PUT my_index/_doc/1 { "title": "hello world", "views": 1234, "public": true, "created": "2025-10-12T14:05:01.234Z" }예시 응답
{ "_index": "my_index", "_id": "1", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_seq_no": 0, "_primary_term": 1 }
이때 _id를 지정하지 않고 문서 내용만 포함한다면, ES가 자체적으로 _id를 할당합니다.
예시 요청
POST my_index/_doc { "title": "hello world2", "views": 1234, "public": true, "created": "2025-10-12T14:05:01.234Z" }예시 응답
{ "_index": "my_index", "_id": "PITK2JkBZ7RTtioO4zwx", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_seq_no": 1, "_primary_term": 1 }
💡
_id를 지정하지 않아 ES가 자체적으로PITK2JkBZ7RTtioO4zwx라는_id를 생성합니다.
_id를 지정하지 않을 떄에는 POST 메서드를 사용해야 합니다.
2. 문서 조회
문서를 조회할때는 인덱스 이름과 _id 값을 지정합니다.
GET [인덱스 이름]/_doc/[_id값]
예시 요청
GET my_index/_doc/1예시 응답
{ "_index": "my_index", "_id": "1", "_version": 1, "_seq_no": 0, "_primary_term": 1, "found": true, "_source": { "title": "hello world", "views": 1234, "public": true, "created": "2025-10-12T14:05:01.234Z" } }
결과의 _source 필드에서 방금 색인한 문서의 내용을 확인할 수 있습니다
3. 문서 업데이트
문서를 업데이트할 때는 인덱스, _id값이 필요합니다. 요청 본문에는 부분 업데이트할 내용을 지정합니다.
업데이트시에는 _doc 대신 _update를 사용합니다.
POST [인덱스 이름]/_update/[_id값]
{
"doc": {
[문서 내용]
}
}
예시 요청
POST my_index/_update/1 { "doc": { "title": "hello ES!" } }예시 응답
{ "_index": "my_index", "_id": "1", "_version": 2, "result": "updated", "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_seq_no": 2, "_primary_term": 1 }
4. 문서 검색
엘라스틱서치는 다양한 검색 쿼리를 가지고 있습니다. 검색을 위해서는 인덱스 이름을 지정하고 뒤에 _search를 붙여 GET 메서드를 사용합니다.
요청 본문에는 엘라스틱서치 쿼리를 넣습니다.
그러나 GET 메서드에 요청 본문을 넣는 것에 대해서는 이견이 있을 수 있습니다만, ES측에서는 검색 특성상 POST보다는 GET이 의도와 더 맞다고 판단했습니다.
RFC7231에서 HTTP의 GET 요청에 본문을 포함하는 것을 허용하지 않던 규칙을 수정하였음에도, 유연성을 위해 ES는 GET과 POST 메서드 모두를 지원합니다.
GET [인덱스 이름]/_search
POST [인덱스 이름]/_search
다음은 match쿼리를 사용한 기본적인 요청입니다.
예시 요청
GET my_index/_search { "query": { "match": { "title": "hello world" } } }예시 응답
{ "took": 1, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 2, "relation": "eq" }, "max_score": 0.18232156, "hits": [ { "_index": "my_index", "_id": "PITK2JkBZ7RTtioO4zwx", "_score": 0.18232156, "_source": { "title": "hello world2", "views": 1234, "public": true, "created": "2025-10-12T14:05:01.234Z" } }, { "_index": "my_index", "_id": "1", "_score": 0.18232156, "_source": { "title": "hello ES!", "views": 1234, "public": true, "created": "2025-10-12T14:05:01.234Z" } } ] } }
hello world 문자열로 검색했더니 문서 두 개가 검색되었습니다.
"hello ES!" 문서도 검색된 것이 확인됩니다. _score에서 유사도 점수도 확인할 수 있습니다.
ES는 전문검색을 위해 토큰화 및 역색인을 사용하기 때문에 위와 같이 단어가 전체 일치하지 않더라도 문서를 검색할 수 있습니다. 토큰화와 역색인의 자세한 내용은 추후에 다른 챕터에서 다뤄보겠습니다.
5. 문서 삭제
DELETE [인덱스 이름]/_doc/[_id값]
예시 요청
DELETE my-index/_doc/1
예시 응답
{
"_index": "my-index",
"_id": "1",
"_version": 1,
"result": "not_found",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
엘라스틱 서치 구조
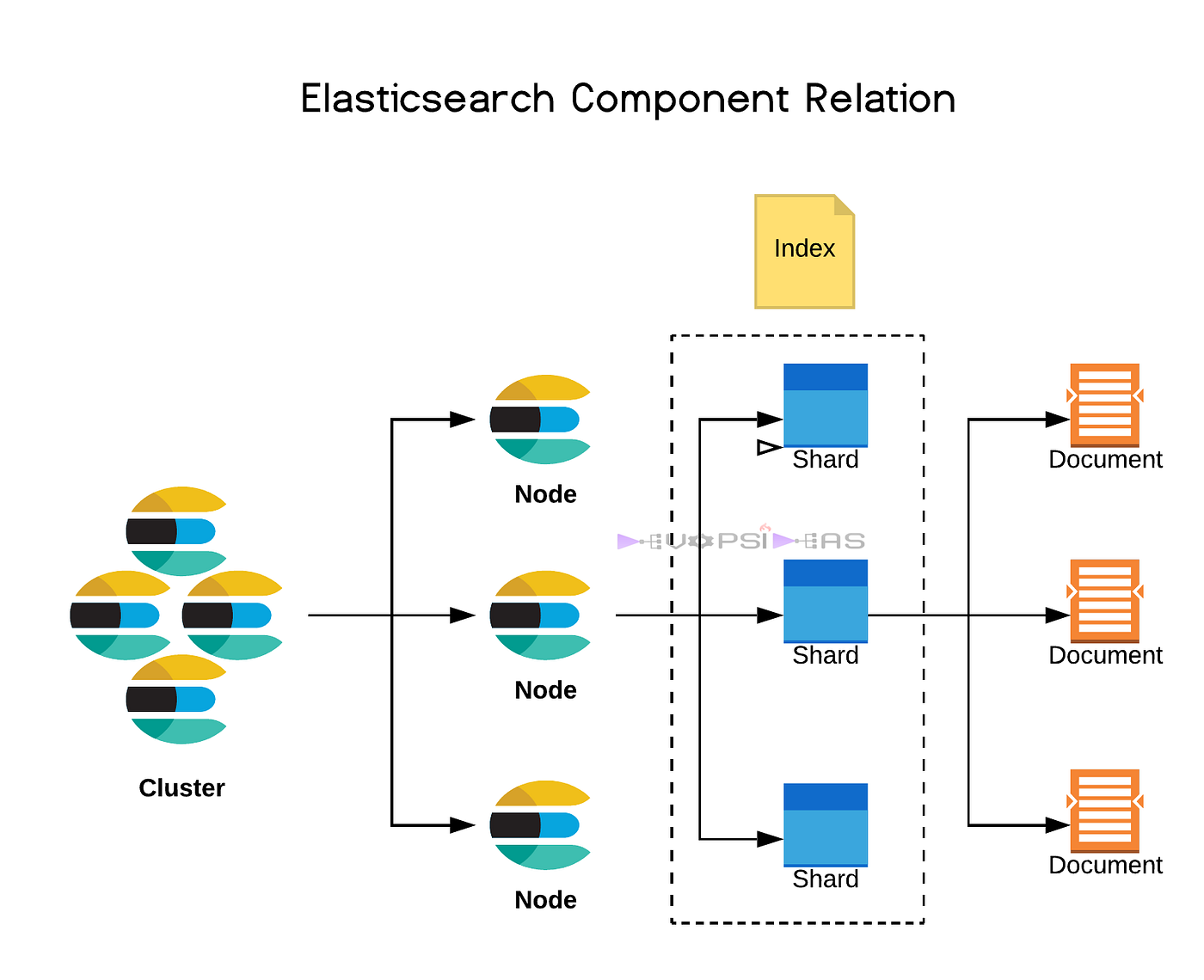
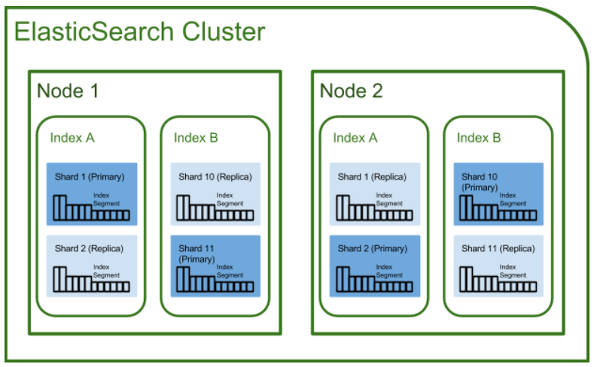
바텀업 형식으로 하나씩 살펴보겠습니다.
먼저 문서(Document)입니다. ES에서 관리하는 Json 문서를 의미합니다.
샤드(Shard)는 문서의 모음입니다. 여러 문서가 모여 복수개의 샤드를 이룹니다.
앞서 샤드가 문서의 모음이라고 했습니다. 샤드는 사실 하나의 인덱스(Index)를 분리한 것입니다. 고로 여러 문서가 모여 하나의 인덱스를 만들고, 그 인덱스를 분리하여 관리하는 단위를 샤드라고 보는 것이 바람직합니다.
그리고 이런 샤드들을 관리하는 주체가 바로 노드(Node)입니다. (정확히 말하면 Data 노드 입니다.)
하나의 노드에는 여러 샤드가 포함될 수 있으나, 동일 인덱스의 primary 샤드와 replica 샤드는 같은 노드에 배치되지 않습니다. 이는 고가용성을 보장하기 위한 것으로, 노드 하나가 비활성화 되더라도, 다른 노드의 복제본 샤드를 활성화 시켜 가용성을 확보할 수 있기 때문입니다. (이를 Promotion 이라고 합니다. ♟️)
ES의 노드들은 Master, Data, Ingest 등 여러 역할 중 하나 이상의 역할을 맡아 하며, 실제 샤드를 가지고 있는 노드는 Data 노드 입니다. Master 노드는 각 후보 중 1대가 선출되어 클러스터를 관리합니다. 1대만 활성화 됩니다. Ingest 노드는 클라이언트 요청을 받아 전처리 후 Data 노드에 분배하는 역할을 합니다.
엘라스틱서치 내부 구조 및 루씬 라이브러리
엘라스틱서치는 아파치 루씬을 코어 라이브러리로 사용합니다. 루씬은 문서를 색인하고 검색하는 라이브러리입니다.
루씬 flush
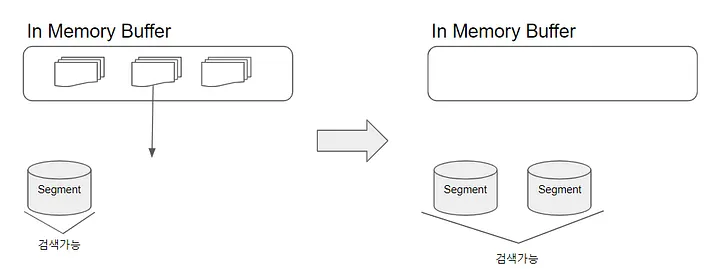
루씬(Lucene)은 새로 추가되거나 수정된 문서를 먼저 메모리 버퍼(In-Memory Buffer) 에 저장합니다. 이때 색인(Index)은 아직 디스크에 완전히 기록되지 않은 상태이며, 메모리 안에서만 유지됩니다. 문서가 추가(addDocument), 수정(update), 삭제(delete)될 때마다 이러한 변경 사항은 즉시 반영되는 것이 아니라, 버퍼에 누적됩니다.
일정량의 데이터가 쌓이거나, 메모리 한계에 도달하거나, 명시적인 트리거가 발생하면 루씬은 이 메모리 버퍼의 내용을 Segment 단위로 디스크에 flush합니다. 즉, 버퍼에 있던 문서들을 새로운 세그먼트(Segment) 파일로 변환하여 디스크에 저장하는 것입니다.
이 과정을 통해 역색인(Inverted Index)의 최초 생성이 이루어집니다. 그 후, 여러 개의 세그먼트가 존재하게 되면, 루씬은 이를 주기적으로 merge하여 더 큰 세그먼트로 통합합니다. 이 merge 과정은 검색 성능을 높이고, 삭제된 문서를 실제로 제거하는 역할도 함께 수행합니다.
이러한 작업을 ES에서는 "refresh"라고 합니다.
루씬 commit
루씬(Lucene)의 commit은 flush 이후 단계로, 메모리에만 존재하거나 OS의 페이지 캐시에 머물러 있던 데이터를 디스크에 완전히 영구 저장(persist)하는 과정입니다.
flush는 단순히 메모리 버퍼의 데이터를 세그먼트 파일 형태로 파일 시스템 캐시(page cache)에 넘겨주는 작업일 뿐, 디스크 기록 자체를 보장하지 않습니다. 즉, flush 직후 시스템이 비정상 종료되면 해당 세그먼트 파일은 실제 디스크에 쓰이지 않았을 가능성이 있습니다.
반면, commit은 fsync() 시스템 콜을 호출하여 페이지 캐시에 있던 세그먼트 파일을 디스크까지 동기화(sync)합니다. 이 과정을 통해 세그먼트의 인덱스 데이터, 메타데이터, 그리고 세그먼트 목록을 담고 있는 segments_N 파일이 디스크에 안전하게 저장됩니다. commit 시점에 생성된 segments_N 파일은 루씬이 “현재 인덱스에 어떤 세그먼트들이 존재하는지”를 식별할 수 있게 해주는 핵심 메타정보입니다.
엘라스틱서치의 flush는 이 루씬 commit을 포함하여 실행됩니다. 일반적으로 엘라스틱서치의 flush 작업은 엘라스틱서치의 refreah 작업보다 훨씬 무겁습니다.
Elasticsearch에서의 commit 활용
Elasticsearch는 내부적으로 여러 샤드가 각각 독립적인 루씬 인덱스를 관리하며, 각 샤드마다 자체적인 commit 주기를 가집니다. ES는 다음 두 가지 수준에서 commit을 제어합니다:
-
루씬 수준 자동 commit
루씬은 flush 이후 일정 주기나 조건(예: 인덱싱 문서 수, 메모리 사용량, 시간 경과)에 따라 자동 commit을 수행하여 segments_N 파일을 업데이트합니다. 이는 데이터 손실을 최소화하면서 성능을 유지하기 위한 루씬의 내부 정책입니다. -
Elasticsearch의 translog(트랜잭션 로그) 관리
Elasticsearch는 루씬 commit이 완료되기 전이라도, 인덱싱 요청을 translog(트랜잭션 로그)에 먼저 기록합니다. 이 translog는 디스크에 fsync되어 있어, 시스템 장애가 발생하더라도 미처 commit되지 않은 변경 사항을 복구할 수 있습니다. 루씬 commit이 수행되면 Elasticsearch는 해당 시점까지의 translog를 “안전하게 반영되었다”고 판단하고 truncation(정리)을 수행합니다. 즉, 루씬 commit은 Elasticsearch의 durability(내구성) 경계선으로 동작합니다.
💡
translog
엘라스틱서치에 색인된 문서들은 루신 commit 이후에야 안전히 기록됩니다.그러나 큰 비용이 드는 commit 작업을 매번 하기에는 부담이 되므로 모아서 배치형태로 작업합니다.
그래서 장애가 발생하는 경우 일부 데이터가 누락될 수 있는데, 이를 방지하기 위해 엘라스틱서치 샤드는 모든 작업마다 translog라는 작업 로그를 남깁니다.
translog는 색인, 삭제 작업이 루씬 인덱스에 수행된 직후에 기록되어, translog 기록이 끝나야만 작업 요청이 성공으로 승인됩니다.
장애가 발생한 경우 translog를 통해 루씬 commit에 포함되지 않은 내용을 샤드 복구 단게에서 복구합니다.
루씬 인덱스와 엘라스틱서치 인덱스
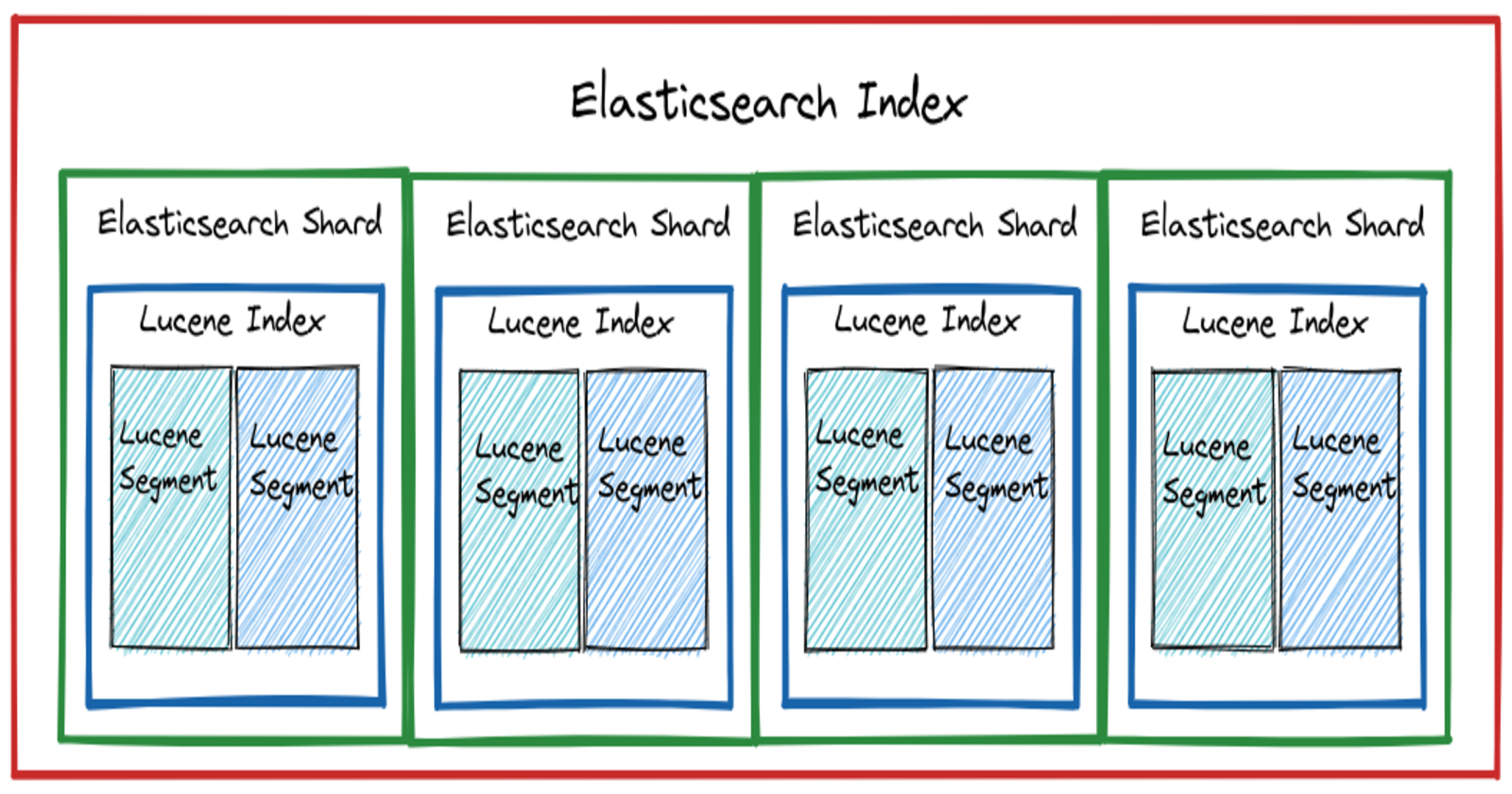
여러 세그먼트가 모이면 하나의 루씬 인덱스가 됩니다.
루씬은 이 인덱스 내에서만 검색이 가능합니다.
엘라스틱서치 샤드는 이 루씬 인덱스 하나를 래핑한 단위입니다.
엘라스틱서치 샤드 여러개가 모이면 엘라스틱서치 인덱스가 됩니다.
ES 레벨에서는 여러 샤드에 있는 문서를 모두 검색할 수 있습니다.
새 문서가 들어오면 해당 내용을 여러 샤드에 분산시켜 저장, 색인하고, 검색 요청이 들어오면 각 샤드를 대상으로 검색 한 뒤 그 결과를 병합하여 최종 응답을 만듭니다.
이 과정을 통해 루씬 레벨에서는 불가능한 분산 검색을 ES 레벨에서 구현합니다.
✅ 예시 세그먼트 구조
Index (루씬 인덱스) ├── Segment A │ ├── file1 │ ├── file2 │ └── file3 ├── Segment B │ ├── file1 │ └── file2 └── Segment C └── file1
✅ Elasticsearch Index (논리)
└── index_uuid/ └── shard_0/ ← Lucene index ├── segments_N ← 인덱스 메타데이터 (가변) ├── Segment _0 ← 논리 개념 │ ├── _0.si │ ├── _0.tim │ ├── _0.doc │ └── _0.pos ├── Segment _1 │ ├── _1.si │ ├── _1.tim │ └── _1.doc └── Segment _2 (CFS) ├── _2.cfs └── _2.si