엘라스틱서치 인덱스 설계 2

🔍 엘라스틱서치 스터디 시리즈
애널라이저와 토크나이저
text필드의 데이터는 애널라이저를 통해 분석돼 여러 텀(term)으로 쪼개져 색인됩니다.
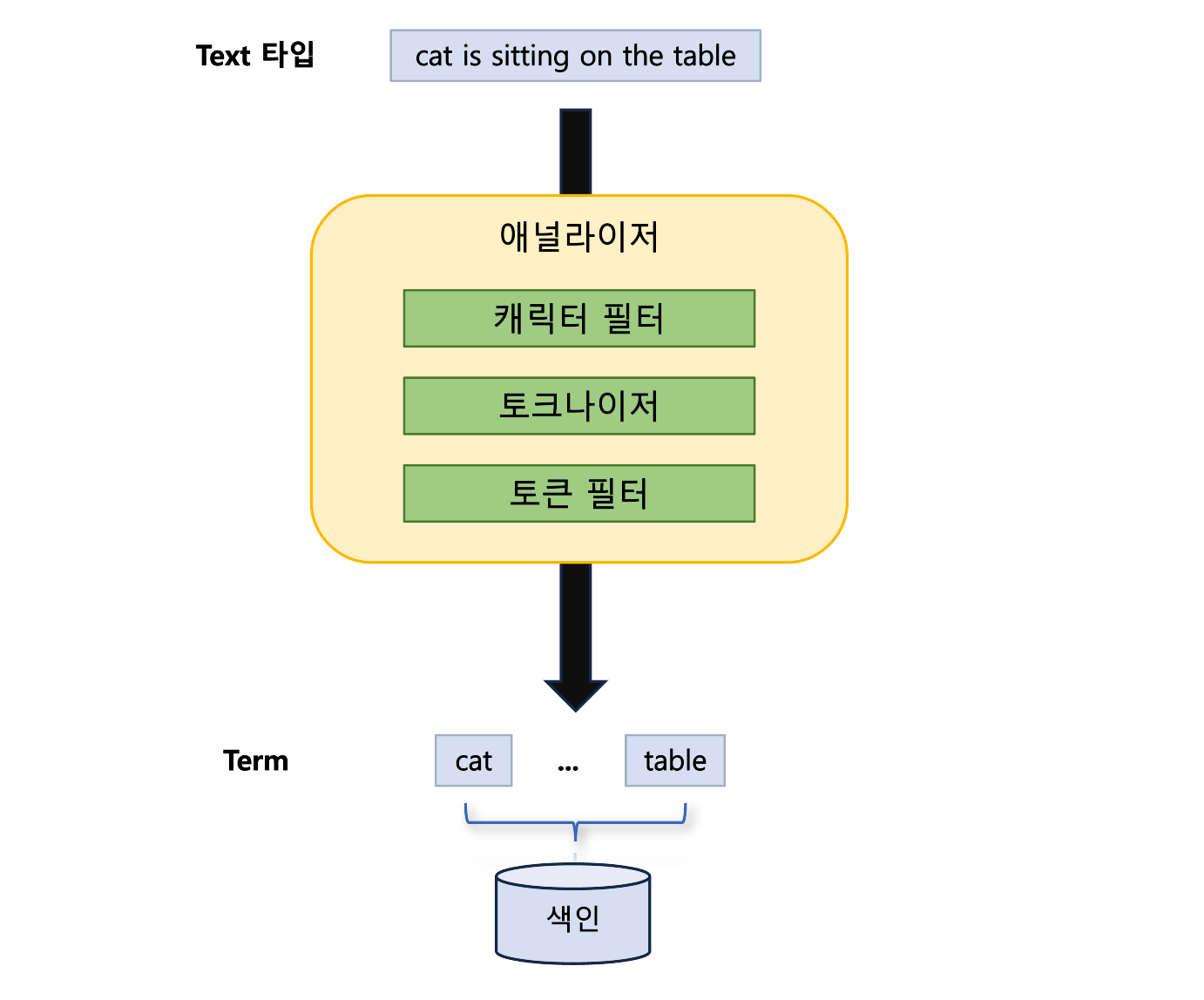
애널라이저는 다음과 같은 요소로 구성됩니다.
- 0개 이상의 캐릭터 필터: 문자열을 변형시킨다.
- 1개의 토크나이저: 여러 토큰으로 쪼갠다.
- 0개 이상의 토큰 필터: 후처리(변형)한다.
각각에 대해 알아봅시다.
analyze API
엘라스틱서치는 애널라이저와 각 구성 요소의 동작을 간편하게 테스트해볼 수 있는 analyze API를 제공합니다.
GET _analyze
POST _analyze
가장 기본적인 standard 애널라이저의 분석 결과를 확인해봅시다.
요청 예시
POST _analyze { "analyzer": "standard", "text": "간장, 공장, 공장장" }응답 예시
{ "tokens": [ { "token": "간장", "start_offset": 0, "end_offset": 2, "type": "<HANGUL>", "position": 0 }, { "token": "공장", "start_offset": 4, "end_offset": 6, "type": "<HANGUL>", "position": 1 }, { "token": "공장장", "start_offset": 8, "end_offset": 11, "type": "<HANGUL>", "position": 2 } ] }
1. 캐릭터 필터
캐릭터 필터는 text를 캐릭터의 스트림으로 받아서 특정한 문자를 추가, 변경, 삭제합니다.
애널라이저에는 0개 이상의 캐릭터 필터를 지정할 수 있습니다. 각 캐릭터 필터는 순서대로 수행됩니다.
내장 빌트인 필터로는 다음과 같은 것들이 있습니다.
HTML strip필터: HTML 태그를 제거하고 텍스트만 남긴다.mapping필터: 특정 문자열이나 문자를 다른 문자로 치환한다.pattern replace필터: 정규식을 이용해 특정 패턴을 다른 문자열로 바꾼다.
2. 토크나이저
토크나이저는 캐릭터 스트림을 받아서 여러 토큰으로 쪼개어 토큰 스트림을 만듭니다. 애널라이저에는 한 개의 토크나이저만 지정할 수 있습니다.
standard 토크나이저
가장 기본적인 토크나이저입니다. Unicode Text Segmentation 알고리즘을 사용하여 텍스트를 단어 단위로 나눕니다. 대부분의 문장 부호를 제거합니다.
standard 애널라이저에서 사용됩니다.
keyword 토크나이저 들어온 텍스트를 쪼개지 않고 그대로 내보냅니다. 특별한 동작을 수행하지 않습니다.
ngram 토크나이저
텍스트를 min_gram ~ max_gram의 단위로 쪼갭니다.
token_chars라는 속성을 통해 토큰에 포함시킬 타입의 문자를 지정할 수 있습니다.
| 종류 | 설명 |
|---|---|
| Letter | 알파벳 또는 한글 등 문자로 구성된 글자 |
| Digit | 숫자(0~9)로 구성된 문자 |
| whitespace | 공백, 탭, 줄바꿈 문자 등 |
| punctuation | 마침표, 쉼표 등 문장 부호 |
| symbol | 기호 문자(예: @, #, $, %) |
| custom | 사용자 정의 문자 세트 |
edge_ngram 토크나이저
ngram토크나이저와 유사한 동작을 수행하나, 모든 토큰의 시작 글자를 단어의 시작 글자로 고정합니다.
3. 토큰 필터
토큰 필터는 토큰 스트림을 받아서 토큰을 추가, 변경, 삭제합니다. 토큰 필터는 여러개 지정할 수 있으며, 순서대로 적용됩니다.
| 필터명 | 설명 |
|---|---|
| lowercase | 모든 토큰을 소문자로 변환한다. |
| uppercase | 모든 토큰을 대문자로 변환한다. |
| stop | 불용어(stopword)를 제거한다. |
| synonym | 지정된 동의어 사전을 기반으로 토큰을 치환하거나 확장한다. |
| asciifolding | 액센트나 특수 문자가 포함된 문자를 기본 라틴 문자로 변환한다. |
| snowball | 어간 추출(영어 등) 필터로, 단어의 기본 형태를 찾아준다. |
| trim | 토큰 앞뒤의 공백 문자를 제거한다. |
| unique | 중복된 토큰을 제거한다. |
내장 애널라이저
위에서 살펴본 1.캐릭터 필터 + 2.토크나이저 + 3.토큰 필터 를 조합하여 애널라이저가 구성됩니다. 엘라스틱서치는 내장된 각 요소를 조합해서 만든 내장 애널라이저를 제공합니다. 그 중 몇가지를 소개하자면 다음과 같습니다:
standard애널라이저: 가장 기본적인 애널라이저로, standard tokenizer와 lowercase, stop 필터를 사용한다.simple애널라이저: 비문자(non-letter)를 기준으로 분리하고 모두 소문자로 변환한다.whitespace애널라이저: 공백 문자 기준으로 토큰을 분리하며, 추가 필터는 적용하지 않는다.keyword애널라이저: 입력된 전체 텍스트를 하나의 토큰으로 처리한다.pattern애널라이저: 정규식 패턴을 기반으로 텍스트를 분리한다.language애널라이저: 영어, 프랑스어 등 특정 언어에 특화된 어간 추출과 불용어 제거를 수행한다.
애널라이저를 매핑에 적용해보기
실제로 애널라이저를 적용해봅시다. 먼저 테스트할 인덱스를 생성합니다:
PUT analyzer_test
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "keyword" // 기본 애널라이저 설정: keyword
}
}
}
},
"mappings": {
"properties": {
"defaultText": { // 필드1: defaultText
"type": "text"
},
"standardText": { // 필드2: standardText
"type": "text",
"analyzer": "standard"
}
}
}
}
defaultText에는 따로 애널라이저를 지정하지 않았으므로 keyword 애널라이저가 적용됩니다.
standardText에는 standard애널라이저를 명시적으로 지정했습니다.
커스텀 애널라이저
내장 애널라이저로 원하는 기능을 수행할 수 없다면 커스텀 애널라이저 사용을 고려할 수 있습니다.
PUT analyzer_test2
{
"settings": {
"analysis": {
"char_filter": { // 캐릭터 필터 지정
"my_char_filter": { // my_char_filter라는 이름의 필터를 만듭니다.
"type": "mapping",
"mappings": [
"i. => 1.",
"ii. => 2.",
"iii. => 3.",
"iv. => 4."
]
}
},
"analyzer": { // 애널라이저 지정
"my_analyzer": { // 커스텀 애널라이저로 my_analyzer라는 이름의 애널라이저를 만듭니다.
"char_filter": [ // 해당 애널라이저는 my_char_filter를 사용합니다.
"my_char_filter"
],
"tokenizer": "whitespace", // 토크나이저로 whitespace를 사용합니다.
"filter": [ // 토큰 필터로 lowercase를 사용합니다.
"lowercase"
]
}
}
}
},
"mappings": {
"properties": {
"myText": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
해당 애널라이저를 사용해보겠습니다.
예시 요청
GET analyzer_test2/_analyze { "analyzer": "my_analyzer", "text": "i.Hello ii.World iii.Bye, iv.World!" }예시 응답
{ "tokens": [ { "token": "1.hello", "start_offset": 0, "end_offset": 7, "type": "word", "position": 0 }, { "token": "2.world", "start_offset": 8, "end_offset": 16, "type": "word", "position": 1 }, { "token": "3.bye,", "start_offset": 17, "end_offset": 25, "type": "word", "position": 2 }, { "token": "4.world!", "start_offset": 26, "end_offset": 35, "type": "word", "position": 3 } ] }
노멀라이저
노멀라이저는 애널라이저와 비슷한 역할을 하지만 적용 대상이 text가 아닌 keyword타입입니다. 출력으로 단일 토큰을 생성합니다.
템플릿
인덱스를 생성할 때마다 설정값을 매번 지정하면 비용이 너무 비싸다는 문제가 있습니다. 템플릿을 지정하여 반복작업이 야기하는 휴먼에러를 줄일 수 있습니다.
인덱스 템플릿
인덱스 템플릿은 다음과 같이 생성합니다. index_patterns 부분에는 인덱스 패턴을 지정합니다. 새로 생성되는 인덱스의 이름이 이 패턴에 부합하면 이 템플릿에 맞춰 인덱스가 생성됩니다.
priority는 여러 인덱스 템플릿간의 우선 적용순위를 조정하는 역할을 합니다.
PUT _index_template/my_template
{
"index_patterns": [
"pattern_test_index-*",
"another_pattern-*"
],
"priority": 1,
"template": {
"settings": {
"number_of_shards": 2,
"number_of_replicas": 2
},
"mappings": {
"properties": {
"myTextField": {
"type": "text"
}
}
}
}
}
컴포넌트 템플릿
인덱스 템플릿을 많이 사용하다보면 템플릿 간 중복되는 부분이 생깁니다. 이런 중복 부분을 재사용할 수 있는 블록단위로 쪼갠 것을 컴포넌트 템플릿이라고 부릅니다.
PUT _component_template/timestamp_mappings
{
"template": {
"mappings": {
"properties": {
"timestamp": {
"type": "date"
}
}
}
}
}
PUT _component_template/my_shard_settings
{
"template": {
"settings": {
"number_of_shards": 2,
"number_of_replicas": 2
}
}
}
이제 인덱스를 생성할 때 사용할 컴포넌트 템플릿 블록을 composed_of 항목에 넣으면 됩니다.
PUT _index_template/my_template2
{
"index_patterns": ["timestamp_index-*"],
"composed_of": ["timestamp_mappings", "my_shard_settings"]
}
동적 템플릿
동적 템플릿은 인덱스에 새로 들어오는 필드의 매핑을 사전에 정의한대로 동적 생성하는 기능입니다.
PUT _index_template/dynamic_mapping_template
{
"index_patterns": ["dynamic_mapping*"], // 해당 패턴과 일치하는 인덱스가 생성된 경우 자동 적용된다.
"priority": 1,
"template": {
"settings": {
"number_of_shards": 2,
"number_of_replicas": 2
},
"mappings": {
"dynamic_templates": [ // 동적 템플릿은 dynamic_templates 안에 지정한다.
{
"my_text": { // my_text라는 이름의 동적 템플릿을 지정한다.
"match_mapping_type": "string",
"match": "*_text",
"mapping": {
"type": "text"
}
}
},
{
"my_keyword": { // my_keyword라는 이름의 동적 템플릿을 지정한다.
"match_mapping_type": "string",
"match": "*_keyword",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
}
라우팅
라우팅은 엘라스틱서치가 인덱스를 구성하는 샤드 중 어떤 샤드를 대상으로 작업을 수행할지 지정하기 위해 사용됩니다.
라우팅 값은 색인시마다 문서마다 하나씩 지정할 수 있습니다.
작업 대상 샤드 번호는 지정된 라우팅 값을 해시하여 주 샤드 개수로 나머지 연산하여 결정됩니다. 라우팅 값을 따로 지정하지 않는다면 _id를 기준으로 라우팅이 진행됩니다.
예시를 통해 확인해봅시다:
PUT routing_test
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}
PUT routing_test/_doc/1?routing=myid
{
"login_id": "myid",
"comment": "hello world",
"created_at": "2025-10-16T01:00:00.123Z"
}
위 예시는 5개의 샤드를 가진 인덱스를 생성한 뒤 myid라는 값을 라우팅 값으로 지정하여 문서를 색인했습니다.
myid를 기반으로 샤드가 선택될 것인데요, 여기서 선택된 샤드를 3번 샤드라고 가정하겠습니다.
문서를 검색할 때 라우팅 값을 포함하여 검색을 하게 되면, 검색할 샤드의 개수를 줄일 수 있습니다. 위의 예시에서라면
GET routing_test/_search?routing=myid 를 실행했을 때 3번 샤드만 검색하여 성능 향상을 꾀할 수 있습니다.
라우팅 값은 성능 향상을 이룩하는 가장 쉬운 방법 중 하나이므로, 웬만한 상황에서는 지정해주는 것이 좋겠습니다. 함께 자주 검색되는 데이터라면 같은 샤드에 몰아 넣는 것이 성능상 이득일 것입니다.
인덱스 매핑 시 라우팅을 필수로 지정하기
라우팅 필수로 지정한 인덱스 생성
PUT routing_test2
{
"mappings": {
"_routing": {
"required": true
}
}
}
라우팅 없이 문서 넣어보기
PUT routing_test2/_doc/1
{
"comment": "index without routing"
}
예상 에러 메시지
- 라우팅이 필수인 인덱스에 라우팅 없이 색인/갱신/삭제를 시도하면 HTTP 400과 함께 아래와 같은 오류가 발생합니다.:
{
"error": {
"type": "routing_missing_exception",
"reason": "routing is required for [routing_test2]/_doc/1",
"index": "routing_test2"
},
"status": 400
}
💡 왜 라우팅을 필수로 지정하도록 강제할까요?
- 샤드 타겟팅 보장: 항상 같은 라우팅 키로 동일 샤드에 쓰고 읽게 되어, 검색 시
?routing=...만으로 스캔 샤드 수를 최소화.- 데이터 로컬리티: 같은 테넌트/사용자/그룹의 문서를 한 샤드에 모아 terms lookup, 집계 등의 비용을 낮출 수 있습니다..
- 일관성 있는 접근 패턴: 애플리케이션에서 라우팅 키 사용을 강제해, 실수로 라우팅을 빼먹어 읽기/갱신 누락이 나는 것을 예방할 수 있습니다.
언제 유용한가
- 멀티 테넌시:
tenantId/miIdx/userId기준 강제 라우팅. 테넌트별 쿼리가 잦고 데이터가 큰 서비스에 적합합니다.- 타임라인/피드: 작성자/채널 단위 라우팅으로 읽기 레이턴시와 캐시 효율을 높일 수 있습니다.
- 부분 범위 반복 조회: 특정 키 기준으로 좁은 범위를 반복 조회할 때 스캔 샤드를 줄여줍니다.
정상 요청 예시
PUT routing_test2/_doc/1?routing=myid { "comment": "index with routing" } GET routing_test2/_search?routing=myid { "query": { "match_all": {} } }