JVM Compressed OOPs
Compressed OOPs란 무엇인가?
OOPs(Ordinary Object Pointers)는 JVM 내부에서 힙 객체의 참조 주소를 가리키는 포인터를 뜻합니다.
자바 코드에서 new Object()로 생성된 객체의 메모리 주소를 가리키는 내부 포인터입니다.
Compressed OOPs는 이름에서 알 수 있듯 "압축된 포인터"로 이해할 수 있는데요.
32비트 시스템과 64비트 시스템을 중심으로 이에 대해 알아봅시다.
32비트 vs 64비트

32비트 시스템
- 32비트 주소 버스와 64비트 데이터 버스를 가지는 Pentium -
32비트 CPU는 주소 버스(Address Bus) 폭이 32비트입니다. (레지스터 폭과 주소 버스 폭이 다른 CPU 아키텍처도 존재하나 예외로 생각하겠습니다.) 즉, 한 번에 32개의 비트를 사용해 메모리의 주소를 지정할 수 있습니다.
2^32 = 4,294,967,296 byte = 4GB
이 말은 CPU가 직접 접근할 수 있는 물리적 메모리 주소가 4GB 범위라는 뜻이고 이 주소를 전부 커버하기 위해서는 주소 버스 폭과 동일하게 4바이트(32비트) 포인터(OOPs)가 필요합니다.
32비트 시스템에서 주소는 다음과 같이 표현됩니다:
0x7FFF_FFFF (최대 표현 가능한 메모리: 4GB)
8바이트 자료형인 double 을 메모리상에 저장한다고 가정해봅시다.
0x7FFF_FFF8
0x7FFF_FFF9
0x7FFF_FFFA
0x7FFF_FFFB
...
...
0x7FFF_FFFE
0x7FFF_FFFF
각 주소 포인터는 1바이트씩을 나타내므로, 위와 같이 8개의 주소 공간을 차지하게 될 것입니다.
64비트 시스템
64비트 CPU는 주소 버스(Address Bus) 폭이 64비트입니다.
즉, 한 번에 64개의 비트를 사용해 메모리의 주소를 지정할 수 있습니다.
2^64 = 16,777,216 TB (약 16 ExaByte)
이론적으로는 16EB의 메모리 공간에 접근할 수 있지만, 실제 하드웨어나 운영체제는 이 전체 공간을 전부 활용하지 않습니다.
예를 들어, 대부분의 x86-64 아키텍처는 **48비트 논리 주소(256TB)**까지만 사용합니다.
이제 중요한 차이점이 생깁니다.
64비트 주소를 표현하려면 포인터(즉, OOPs)의 크기가 주소 버스 폭과 동일하게 8바이트(64비트)가 되어야 합니다.
그 결과:
- 객체 참조 필드, 배열 요소, 객체 헤더 등 포인터를 포함하는 모든 데이터 구조의 크기가 증가합니다.
- 동일한 데이터를 저장하더라도 32비트 JVM보다 메모리를 약 30~40% 더 많이 사용하게 됩니다.
- 이는 CPU 캐시 효율(CPU Cache Locality)에도 부정적인 영향을 줍니다.
이런 비효율을 해결하기 위해 등장한 기술이 바로 Compressed OOPs입니다.
64비트 JVM이지만, 객체 참조 포인터를 32비트로 “압축(Compress)”하여 메모리 공간을 절약하고,
64비트 주소 공간의 장점(4GB 이상의 힙 메모리 지원)은 그대로 유지합니다.
64비트 시스템에서는 주소가 다음과 같이 표현됩니다:
0x0000_7FFF_FFFF_FFFF (최대 표현 가능한 메모리: 16EB)
이번에도 동일하게 8 byte짜리 double 자료형 하나를 저장한다고 가정해봅시다.
0x0000_7FFF_FFFF_FFF8
0x0000_7FFF_FFFF_FFF9
0x0000_7FFF_FFFF_FFFA
0x0000_7FFF_FFFF_FFFB
...
...
0x0000_7FFF_FFFF_FFFE
0x0000_7FFF_FFFF_FFFF
마찬가지로 각 주소 포인터는 1바이트씩을 나타내므로, 위와 같이 8개의 주소 공간을 차지하게 될 것입니다.
64bit JVM에서 Compressed OOPs의 동작 원리
JVM은 커널의 메모리 관리 구조를 모방하여 동일하게 스택영역, 힙영역, 데이터 영역 등이 존재합니다. 실제 메모리 상에서는 JVM 프로세스 자체가 거대한 힙 메모리 영역을 빌려서 사용하지만, 내부적으로는 그 힙 메모리 영역을 JVM 나름대로 구분하여 사용합니다.
이때, JVM은 각 데이터를 힙 메모리에 저장할때 8바이트 기준으로 패딩을 적용하여 저장하게 됩니다. 이 작업은 32비트와 64비트 모두에서 동일하게 일어나며, 굳이 8바이트 기준으로 패딩을 적용하는 이유는, java의 primitive 타입 중 가장 큰 데이터가 8바이트를 차지하기 때문입니다.
예시를 하나 들어보겠습니다.
힙 메모리가 낮은 주소, 높은 주소 순서로 할당된다는 사실을 인지해주시기 바랍니다.
int(4 byte), double(8 byte)를 차례로 저장한다고 해봅시다.
0x0000_0000_7FFF_0000 이 우리 주소의 시작점이라고 가정해보죠. int를 저장하기 위해서는 아래 4개 주소를 사용해야 할 것입니다:
0x0000_0000_7FFF_0000
0x0000_0000_7FFF_0001
0x0000_0000_7FFF_0002
0x0000_0000_7FFF_0003
그럼, 이어서 double을 저장해볼까요?
double은 8바이트를 차지하기 때문에, JVM은 double 변수를 8의 배수 주소(8-byte aligned address)에 저장합니다.
0x0000_0000_7FFF_0004는 8의 배수가 아니므로, 다음 정렬 가능한 주소인 0x0000_0000_7FFF_0008부터 double을 저장합니다.
0x0000_0000_7FFF_0008
0x0000_0000_7FFF_0009
0x0000_0000_7FFF_000A
0x0000_0000_7FFF_000B
0x0000_0000_7FFF_000C
0x0000_0000_7FFF_000D
0x0000_0000_7FFF_000E
0x0000_0000_7FFF_000F
이 과정에서 0x0000_0000_7FFF_0004부터 0x0000_0000_7FFF_0007까지의 4바이트가 비게 되는데, 이 부분을 패딩(Padding) 이라 부릅니다.
이 정렬 규칙은 단순한 낭비가 아니라 CPU가 데이터를 더 빠르게 읽기 위한 메모리 정렬(Alignment) 최적화 때문인데요,
CPU는 특정 단위(보통 데이터 버스 폭)로 메모리를 읽는데, double이 8바이트 경계에 맞춰져 있으면
CPU는 한 번의 접근으로 값을 읽을 수 있다는 장점이 있습니다.
반면, 경계가 맞지 않으면 두 번의 버스 접근이 필요하므로 성능이 저하됩니다.
따라서 JVM은 모든 객체를 8바이트 경계에 맞춰 저장하며, 이 특성이 Compressed OOPs의 핵심 전제가 됩니다. 여기서 중요한 내용을 이해해야 하는데요,
모든 객체 주소가 8의 배수이므로, 하위 3비트(2³=8)는 항상 0입니다.
조금 더 풀어서 설명한다면,
0x0000_0000_7FFF_0000
0x0000_0000_7FFF_0001
0x0000_0000_7FFF_0002
0x0000_0000_7FFF_0003
0x0000_0000_7FFF_0004
0x0000_0000_7FFF_0005
0x0000_0000_7FFF_0006
0x0000_0000_7FFF_0007
0x0000_0000_7FFF_0008
0x0000_0000_7FFF_0009
0x0000_0000_7FFF_000A
0x0000_0000_7FFF_000B
0x0000_0000_7FFF_000C
0x0000_0000_7FFF_000D
0x0000_0000_7FFF_000E
0x0000_0000_7FFF_000F
이렇게 16개 주소가 있을때, 이 16개 주소를 전부 계산할 필요 없이,
0x0000_0000_7FFF_0000(0)
0x0000_0000_7FFF_0008(8)
이 두 개 주소만 알고 있다면 저장된 데이터를 문제 없이 불러올 수 있다는 뜻입니다. 알아야 할 주소가 8개 -> 1개로 1/8로 줄어든 셈이죠.
즉, JVM은 이 8개 주소(3비트) 를 제거하면서 32비트 오프셋을 저장하여 “압축된 포인터(Compressed OOP)”를 만들 수 있습니다.
💡 왜 3비트인지 헷갈리신다면, 위 주소(
0x0000_0000_7FFFF_0000) 표현에서 각 자리가 16진수로 4비트를 표현 가능하다는 사실을 생각해주세요.
이 압축된 포인터는 실제 주소로 사용할 때 다시 복원됩니다:
실제 주소 = Compressed OOP << 3
예를 들어, 압축된 OOP가 0x0000_0000_00AA_BBCC라면:
실제 주소 = 0x0000_0000_00AA_BBCC << 3 = 0x0000_0000_0555_E660
앞서 32비트 시스템에서는 최대 4GB의 메모리만 사용할 수 있다고 이야기 했습니다. 우리는 여기서 8바이트 정렬(패딩)을 통해 3비트의 여유공간을 더 확보했습니다. 그래서 사실상 35비트를 32비트로 표현할 수 있게 되었습니다.
이를 표현한 그림은 다음과 같습니다.
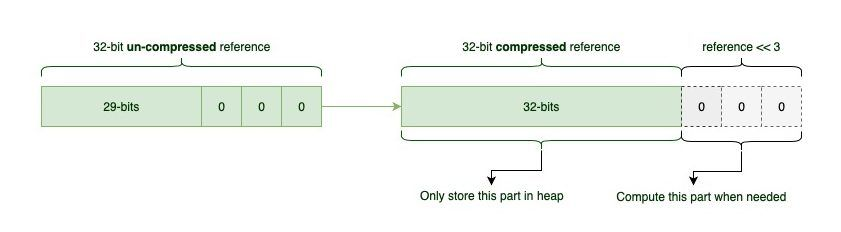
이로써 본래 32비트 포인터로는 4GB까지만 표현할 수 있었던 메모리를, 8바이트 정렬을 이용해 4GB * 8(3비트) = 32GB까지 확장해 표현할 수 있게 되었습니다.
64비트 JVM에서 모든 객체 참조를 64비트 포인터로 처리하는 것은 메모리 효율과 캐시 성능 측면에서 비효율적이기 때문에, JVM은 일정 범위(약 32GB) 내에서는 Compressed OOPs를 활성화해 메모리 사용량을 절감하는 것이 좋습니다.
3비트 shift 연산이 추가된다는 오버헤드가 있지만, 대부분의 워크로드에서 이로 인한 손실보다 메모리 절감 효과가 더 크다고 합니다.
ElasticSearch와 같은 대규모 JVM 애플리케이션에서도 일반적으로 Compressed OOPs 활성화가 강력히 권장되는데요,
다만, Heap이 Zero-based로 할당되지 않는 경우에는 객체 참조 시 base 주소를 더하는 연산이 필요해져 오히려 성능이 저하될 수 있습니다.
즉, Zero-based 모드는 이상적이지만, 커널의 메모리 관리 정책이나 힙 배치 상황에 따라 항상 보장되는 것은 아닙니다.
Non-zero-based 모드에서는 32GB 이상의 힙메모리를 할당받더라도 4바이트 포인터를 유지할 수 있지만, 성능상 단점이 크기(참조 연산마다 base offset이 추가되는 탓에) 때문에 보통 31GB의 힙메모리를 지정하는 것이 관행적으로 표준처럼 자리잡았습니다.