Spring에서 Redis 분산락 적용하기

본 문서에서는 프로젝트에 Redis 분산락을 적용하게 된 배경과 의사결정 과정, 각 락의 특징에 대해 정리해보고자 한다.
공유 자원에 대한 동시 접근 문제는 컴퓨터 과학이 탄생한 초기부터 학계의 화두로 자리잡아 왔다. 생산자-소비자 문제, 식사하는 철학가 문제 등은 모두 동기화 제어 없이 발생할 수 있는 교착 상태와 경쟁 조건을 잘 보여주는 고전적인 예시이다.
락이란?
락(Lock) 은 여러 주체(쓰레드 혹은 프로세스)가 공유 자원에 동시에 접근할 때 발생할 수 있는 경쟁 조건을 방지하기 위한 동기화 기법이다.
락은 한 번에 오직 하나의 주체만 자원에 접근할 수 있도록 제어함으로써, 데이터의 정합성을 어느 정도 보장할 수 있다. 이를 통해 중복 실행, 데이터 손상 등의 문제를 예방할 수 있다.
먼저 이 포스트에서 사용할 각각의 용어부터 정리해보고자 한다.
임계영역
락은 일반적으로 임계 영역을 보호하는 데 사용될 수 있다. 임계 영역이란 여러 주체가 동시에 접근하면 문제가 발생할 수 있는 코드 영역을 의미한다. 락을 통해 이 임계 영역을 보호하면, 한 순간에는 오직 하나의 주체만이 해당 작업을 실행할 수 있게 된다.
뮤텍스와 세마포어
락을 이해하려면, 그 기반이 되는 저수준 동기화 도구인 뮤텍스(Mutex) 와 세마포어(Semaphore) 개념을 짚고 넘어가는 것이 도움이 될 수 있다.
- 뮤텍스(Mutual Exclusion Object)
하나의 스레드만 자원에 접근할 수 있도록 보장하는 락의 대표적인 구현이다. 락을 획득한 스레드만이 해제할 수 있어, 명확한 소유권이 존재한다. 락이 보장해야 할 상호 배제(Mutual Exclusion) 의 본질을 가장 잘 구현한 도구라고 볼 수 있다. - 세마포어(Semaphore)
공유 자원에 동시에 접근할 수 있는 스레드 수를 제한하는 카운터 기반의 동기화 메커니즘이다. 예를 들어, 5개의 커넥션을 가진 DB 풀에서 동시에 5개의 요청만 처리하고자 할 때 사용될 수 있다. 다만, 세마포어는 뮤텍스와 달리 소유권 개념이 없고, 동시에 여러 스레드의 접근을 허용하기 때문에 엄밀히 말해 ‘락’이라고 부르기는 다소 어렵다. 상호 배제를 강제하지 않기 때문이다.
요약하자면, 뮤텍스는 ‘락’이고, 세마포어는 ‘락과는 다른 유형의 동기화 도구’ 라고 할 수 있다.
본 문서에서 락이라는 용어는 주로 뮤텍스의 의미(상호 배제)로 사용될 수 있으니, 참고해주시기 바란다.
⚠️ 오해를 방지하기 위해 덧붙이자면, 세마포어는 카운팅 세마포어와 이진(Binary) 세마포어로 나눌 수 있다. 이진 세마포어는 뮤텍스와 혼동될 수 있지만, 이진 세마포어는 소유권의 개념이 없고, 뮤텍스는 소유권의 개념이 있다. 이진 세마포어도 특정 조건에서는 락의 역할을 수행할 수 있으며, 소유권의 개념이 없기 때문에 좀 더 범용적으로 사용될 수 있다.
락의 종류
락은 동시성 제어 방식의 전략적 관점과 락이 적용되는 시스템 환경이라는 두 가지 주요 기준에 따라 다양하게 분류될 수 있다. 여기서는 대표적인 락의 종류들을 간략히 살펴보고자 한다.
비관적 락 (Pessimistic Lock)
비관적 락은 공유 자원에 접근하기 전에 선제적으로 락을 획득하여, 다른 주체의 접근을 완전히 차단하는 방식이다. 즉, 충돌이 발생할 가능성이 높다고 보고 미리 잠금(Lock) 상태로 만드는 방식이라고 볼 수 있다.
- 주로 다음과 같은 경우에 사용될 수 있다:
- 충돌 가능성이 높은 경우 (잦은 동시 수정이 예상될 때)
- 자원의 상태를 자주 수정하는 경우
예: 관계형 데이터베이스의 SELECT FOR UPDATE 구문, Java의 synchronized 키워드, ReentrantLock
낙관적 락 (Optimistic Lock)
낙관적 락은 자원에 접근할 때 락을 걸지 않고, 작업이 끝난 후 데이터가 변경되지 않았는지 검사하여 충돌을 감지한다. 만약 충돌이 감지되면 작업을 다시 시도(retry) 하도록 할 수 있다.
낙관적 락은 다음과 같은 상황에 유용할 수 있다:
- 충돌 가능성이 낮은 경우 (읽기 작업이 쓰기 작업보다 훨씬 많은 경우)
- 읽기 위주의 작업이 많은 경우
예: JPA의 @Version 필드 기반 버전 관리 (데이터베이스 레코드의 버전 정보를 활용)
분산락 (Distributed Lock)
여러 대의 서버 인스턴스나 독립적인 프로세스가 동일한 공유 자원에 접근하는 환경에서는, 단일 서버/프로세스 내에서만 유효한 락으로는 동기화가 어려울 수 있다. 이러한 상황에서는 분산락이 유용할 수 있다.
분산락은 네트워크를 통해 여러 노드 간의 공유 자원 접근 권한을 제어하며, 대부분의 분산 락 구현은 자원에 접근하기 전에 락을 획득하는, 비관적 락과 유사한 방식을 따르는 경우가 많다. 대표적으로 다음과 같은 솔루션들이 있다:
- Redis 기반 분산락 (예: Redisson, RedLock 알고리즘)
- ZooKeeper 기반 분산락
- etcd 기반 분산락
분산락은 분산 환경에서의 스케줄러 중복 실행 방지, 마이크로서비스 간 공유 자원 보호 등에 유용하게 사용될 수 있다.
락 분류의 관계 정리
위에서 설명한 락의 종류들은 서로 다른 분류 기준에서 파생된 것이다. 비관적 락과 낙관적 락은 주로 '어떻게 충돌을 다룰 것인가'에 대한 전략적인 접근 방식을 의미한다. 반면, 분산 락은 '여러 서버에 걸쳐 자원을 보호해야 할 때' 사용되는 특정 환경에서의 락 구현 방식을 지칭한다고 볼 수 있다.
따라서 분산 락은 그 구현 방식에 따라 비관적 락의 특성(예: 락을 먼저 획득하고 진입)을 가질 수 있다. 즉, 모든 분산 락이 비관적 락은 아니지만, 많은 분산 락 솔루션들이 비관적인 동시성 제어 전략을 채택하고 있다고 이해할 수 있다.
왜 분산락인가?
분산 시스템에서는 단일 인스턴스에서 동작하는 전통적인 락, 예를 들어 데이터베이스 락이나 로컬 뮤텍스만으로는 모든 동시성 문제를 해결하기 어렵다.
특히 여러 대의 서버 인스턴스나 멀티 프로세스 환경에서는, 하나의 DB 트랜잭션 내에서 자원 접근을 제어할 수 없는 상황이 자주 발생한다.
예를 들어, 스프링 스케줄러를 사용해 매 분마다 특정 작업을 수행하는 경우를 생각해보자.
애플리케이션이 여러 인스턴스로 배포되어 있을 경우, 각 인스턴스에서 동시에 스케줄러가 실행될 수 있다.
이때 DB 락이나 트랜잭션 범위로는 서로 다른 인스턴스 간의 실행을 제어할 수 없기 때문에, 동일 작업이 중복 수행되는 문제가 발생할 수 있다.
또한, 마이크로서비스 환경에서는 서로 다른 서비스가 동일 자원(예: 메시지 큐, 외부 API, 파일 등)에 접근할 수 있다.
이 경우 DB 락은 데이터베이스 외부 자원의 동기화까진 보장해주지 못하며, 공유 자원에 대한 글로벌한 제어가 필요한 상황에서는 분산락이 적합하다.
즉, 다음과 같은 경우에 분산락이 필요하다:
- 여러 서버 인스턴스에서 하나의 공유 자원에 접근하는 경우
- DB의 비관적 락 적용에 대한 병목이 심하여 락 관리를 이관하고 싶은 경우
- DB 트랜잭션의 범위를 넘는 외부 자원 동기화(외부 API, 다른 마이크로 서비스, 메시지 큐 등)가 필요한 경우
- 배포된 스케줄러의 중복 실행을 방지해야 하는 경우
이러한 요구사항을 만족하기 위해, Redis와 같은 외부 시스템을 활용한 분산락이 유효한 대안이 될 수 있다.
Redis로 분산락 구현하기
분산락을 구현하기 위해 사용할 수 있는 대표적인 도구 중 하나가 바로 Redis다. Redis는 단일 스레드로 작동하며, 명령 실행 순서가 보장되기 때문에 분산 환경에서 락 관리에 유리한 구조를 가진다.
Redis 분산락의 기본 원리
Redis 분산락은 주로 다음 방식으로 작동한다:
Redis는 단일 스레드 기반으로 동작하며, SET NX PX 같은 명령은 원자적으로 처리되기 때문에 락 획득 시 race condition 없이 안정적으로 작동할 수 있다.
- 클라이언트는 SET key value NX PX timeout 명령을 사용해 락을 요청한다.
- NX: 키가 존재하지 않을 때만 설정한다 (atomic).
- PX timeout: TTL(유효 시간)을 지정해 데드락을 방지한다.
- 락을 성공적으로 획득한 클라이언트만이 특정 작업을 수행한다.
- 락 해제는 오직 락을 획득한 주체만이 해야 하며, 이를 위해 일반적으로 Lua 스크립트 기반의 value 비교 후 삭제 방식이 사용된다.
-- 락 해제 Lua 스크립트 예시
if redis.call("GET", KEYS[1]) == ARGV[1] then
return redis.call("DEL", KEYS[1])
else
return 0
end
Spring에서 Redis 락 적용하기 (with Redisson)
Spring Boot 환경에서 Redis 분산락을 보다 손쉽게 적용하기 위해 널리 사용되는 라이브러리가 Redisson이다. Redisson은 Redis 클라이언트 중 하나로, 락, 세마포어, 큐, 캐시 등 다양한 고수준 자료구조와 동기화 도구를 제공한다. 특히, 락 기능과 관련해서는 RLock 인터페이스를 통해 분산 재진입 락을 손쉽게 사용할 수 있다.
단순히 SET NX PX 같은 명령어만으로는 구현이 까다로운 분산 락의 TTL 관리, 락 해제 시 Lua 스크립트 검증, 자동 연장(watchdog) 기능, 락 해제 시 pub/sub 알림까지 모두 구현되어 있어, 실무에서 바로 적용할 수 있다.
Redisson이란?
Redisson은 다양한 Redis 클라이언트 중에서도 고수준 분산 동기화 도구를 풍부하게 제공하는 라이브러리다. 아래는 Redisson, Lettuce, Jedis 간의 주요 기능 비교다:
| 항목 | Redisson | Lettuce | Jedis |
|---|---|---|---|
| 성격/추상화 | 고수준 분산 구조 제공 (RLock, RMap 등) | 저수준 명령어 기반, 비동기/Reactive 지원 | 저수준 명령어 기반 |
| 분산락 지원 | 내장 (RLock, watchdog, pub/sub) | 직접 구현 필요 | 직접 구현 필요 |
| 동기/비동기 | 지원 | 지원 + Reactive | 주로 동기 |
| Spring 통합 | redisson-spring-boot-starter 제공 |
Spring Data Redis 기본 클라이언트 | 사용 가능 |
| 특징 | 즉시 사용 가능한 분산락, 다양한 객체 지원 | 성능과 안정성 우수 | 단순하고 익숙함 |
| 단점 | 의존성과 리소스 상대적으로 큼 | 락 직접 구현 필요 | 대규모 환경에 부적합 |
RedLock이란?
RedLock은 Redis Labs에서 제안한 분산 환경에서의 락 알고리즘이다. Redis 노드가 여러 개인 경우, 단일 노드의 불안정성을 보완하고자 다중 노드에 동시에 락을 시도하여 과반수(예: 3/5)를 확보했을 때 락을 획득했다고 간주한다.
RLock이란?
Redisson이 제공하는 RLock은 분산 재진입 락 API로, 내부적으로 다음과 같은 기능을 포괄한다:
SET NX PX기반의 락 획득- Lua 스크립트를 통한 소유자 검증 후 해제
- watchdog: 지정한 lease time이 없다면, 기본 30초 단위로 자동 갱신
- pub/sub: 다른 클라이언트는 락 해제를 감지하고 알림받아 효율적으로 대기(바쁜 대기 또는 백오프 없음)
RLock은 RedLock 알고리즘과는 다르며, 단일 Redis 인스턴스 또는 Sentinel/Cluster 환경에서 충분히 안정적이다.
왜 Redis 분산락인가
Redis 분산락을 도입하게 된 배경은 다음과 같은 요구사항 때문이었다:
- 서버 인스턴스가 여러 대인 환경
- 특정 자원(예: 센서 데이터, 결제 처리, 특정 사용자에 대한 작업 등)에 대해 하나의 서버 인스턴스만 접근할 수 있도록 제어해야 했다.
- 이 상황에서 synchronized, JVM 기반 ReentrantLock 같은 로컬 락은 사용할 수 없다.
- 데이터베이스 락의 한계
- 물론 DB 수준의 비관적 락이나 낙관적 락을 사용할 수 있었지만,
- DB 락은 트랜잭션 내부에서만 유지되며,
- 락의 범위가 DB 엔진에 강하게 결합되어 있어 서비스 간 독립성 확보에 제약이 있었다.
- 또한, 락 획득 상태에 대한 Pub/Sub 알림이나 자동 연장 같은 고급 기능이 없어 유연하게 쓰기 어려웠다.
- 직접 구현 시 유지보수 복잡성
- Redis의 SET NX PX를 직접 사용하는 방식도 가능했지만, 다음을 직접 구현해야 했다:
- 락 해제 안전성 (Lua 스크립트)
- 락 만료 시 자동 연장 (Watchdog)
- 락 획득 실패 시 대기 / 재시도 / 백오프
- 다중 인스턴스 환경에서의 동기화 문제
- 이 모든 로직을 우리가 직접 구현하는 대신, Redisson이 제공하는 고수준 추상화를 활용하면 구현과 유지보수가 크게 단순화된다.
- Redisson 선택 이유
- Redisson은 RLock 인터페이스를 통해 분산 락을 매우 직관적으로 구현할 수 있으며, Watchdog, Pub/Sub, 자동 갱신 등을 기본적으로 제공한다.
- 또한, redisson-spring-boot-starter를 통해 Spring과 쉽게 통합되고, 나중에 필요할 수 있는 RMap, RSemaphore, RQueue 같은 분산 구조체도 사용할 수 있다.
실제 코드 구현
분산 시스템에서 여러 인스턴스가 특정 작업을 동시에 처리해야 할 때, 중복 실행을 방지하고 데이터의 정합성을 유지하는 것은 중요하다. 여기서는 Spring Boot 환경에서 Redis 분산락을 활용하여 이러한 동시성 문제를 어떻게 해결했는지 실제 코드 예시를 통해 설명한다.
-
분산락 적용 이전의 스케줄러 구조
먼저, 분산락이 적용되기 전 스케줄러의 기본적인 구조를 살펴보지. 이 스케줄러는 주기적으로 DB에서 처리할 데이터를 배치(Batch) 단위로 조회하여 개별 처리하는 역할을 힌다.@Component @RequiredArgsConstructor public class CommonScheduler { private final CommonSchedulerService commonSchedulerService; // 매 분마다 작동하는 스케줄러 @Scheduled(cron = "0 * * * * *") public void executePollingTask() { commonSchedulerService.processDataBatch(); } }위 스케줄러는 processDataBatch() 메서드를 매 분마다 호출한다. 이 메서드는 CommonSchedulerServiceImpl에 구현되어 있다.
@Service @RequiredArgsConstructor @Slf4j public class CommonSchedulerServiceImpl implements CommonSchedulerService { @Value("${scheduler.task.data-processing.batch-size}") private int DATA_PROCESSING_BATCH_SIZE; // application.yml 등에서 설정 가능 private final DataRepository dataRepository; // 데이터 조회를 위한 레포지토리 private final DataProcessor dataProcessor; // 실제 데이터 처리 로직을 담당하는 서비스 @Override public void processDataBatch() { log.info("데이터 처리 스케줄러 시작"); while (true) { // 1. 배치 사이즈만큼 미처리 데이터 조회 (락 없음) List<ProcessingTarget> targetList = dataRepository.findUnprocessedBatch(DATA_PROCESSING_BATCH_SIZE); log.info("조회된 미처리 데이터 수: {}", targetList.size()); if (targetList.isEmpty()) { log.info("새로운 미처리 데이터 없음. 루프 종료."); break; // 처리할 데이터가 없으면 루프를 종료하고 다음 스케줄링을 기다립니다. } // 2. 각 데이터를 순회하며 개별 처리 for (ProcessingTarget target : targetList) { // 개별 데이터 처리 (이 메서드 내에서 분산락 시도) dataProcessor.processSingleTarget(target); } // 3. 과도한 DB 부하 방지 및 다음 배치를 위한 대기 (백오프 전략) try { Thread.sleep(500, ThreadLocalRandom.current().nextInt(100)); } catch (InterruptedException e) { Thread.currentThread().interrupt(); // 인터럽트 상태 복원 throw new RuntimeException("스케줄러 스레드 인터럽트 발생", e); } } log.info("데이터 처리 스케줄러 종료"); } }이 구조는
processDataBatch()메서드가 주기적으로 미처리 데이터를 조회하여 개별(ProcessingTarget) 단위로 dataProcessor.processSingleTarget()를 호출한다. 여기서 중요한 점은 여러 서버 인스턴스에 스케줄러가 배포되었을 때 발생하는 중복 처리 문제를 어떻게 해결할 것인가이다. 각 ProcessingTarget은 고유한 ID를 가지므로, 이 ID를 기준으로 개별 데이터별로 락을 걸어 처리하기로 결정했다. -
Redisson을 활용한 분산락 직접 구현 예시
초기에는 DataProcessor 서비스 내에서 Redisson RLock을 직접 사용하여 분산락을 구현했다.@Component @RequiredArgsConstructor @Slf4j public class DataProcessor { private final MainEntityRepository mainEntityRepository; // 메인 엔티티 업데이트 레포지토리 private final DataRepository dataRepository; // 데이터 상태 업데이트 레포지토리 private final RedissonClient redissonClient; // RedissonClient 주입 /** * 하나의 데이터를 처리하고 락을 관리하는 메서드 * (분산락을 직접 획득하고 해제하는 로직 포함) */ @Transactional // DB 트랜잭션은 여전히 필요합니다. public void processSingleTarget(ProcessingTarget target) { if (target == null || target.getId() == null || target.getCreationTime() == null) { log.warn("필수 값이 없는 처리 대상 데이터입니다. 무시합니다. 데이터: {}", target); return; // 방어 로직: 필수 값 없으면 무시 } // 락 키는 처리 대상 데이터의 고유 ID를 사용합니다. String lockKey = "lock:processing-target:" + target.getId(); RLock lock = redissonClient.getLock(lockKey); try { // 락 획득 시도: 1초 대기 (waitTime), 락 만료 시간은 Redisson watchdog에 맡김 (-1은 기본값) if (lock.tryLock(1, TimeUnit.SECONDS)) { try { // 이미 처리된 항목인지 재확인 (다른 서버에서 락을 놓쳐 처리했을 가능성, 멱등성 보장) if (Boolean.TRUE.equals(target.isProcessed())) { log.info("이미 처리된 데이터입니다. ID: {}", target.getId()); return; } // 핵심 비즈니스 로직 수행 // 예시: 메인 엔티티의 상태를 최신 데이터 기준으로 업데이트 mainEntityRepository.updateStatusByProcessingTarget( target.getParentId(), // 메인 엔티티 ID target.getCreationTime() ); // 처리 완료 플래그 업데이트 dataRepository.markAsProcessed(target.getId()); log.info("데이터 처리 완료. ID: {}", target.getId()); } finally { // 락을 현재 스레드가 소유하고 있을 때만 해제 if (lock.isHeldByCurrentThread()) { lock.unlock(); } } } else { log.warn("락 획득 실패. 다른 서버에서 이미 처리 중이거나 락이 걸려있습니다. targetId: {}", target.getId()); } } catch (InterruptedException e) { log.error("락 획득 중 인터럽트 발생. targetId: {}", target.getId(), e); Thread.currentThread().interrupt(); // 인터럽트 상태 복원 } } }코드를 통해 각 처리 대상 데이터(target.getId())별로 분산락을 걸어 중복 처리를 방지할 수 있었다. tryLock 메서드는 락 획득에 성공하면 true를, 실패하면 false를 반환하며 지정된 시간 동안 대기할 수 있다. finally 블록에서 isHeldByCurrentThread()를 통해 현재 스레드가 락을 소유하고 있을 때만 해제하도록 하여 안정성을 확보했다.
이 구조의 일반화된 플로우는 다음과 같다. 배치 데이터 조회 시점 이후를 기준으로 한다.
플로우 차트
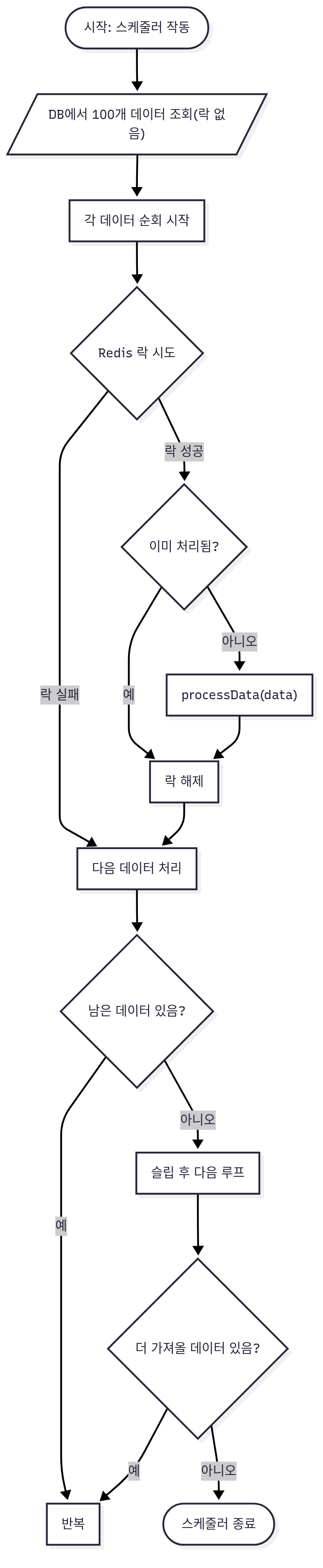
-
AOP를 활용한 분산락 추상화
위에서 구현한 processSingleTarget 메서드는 락 획득 및 해제 로직이 비즈니스 로직과 직접적으로 섞여 있어 재사용성과 유지보수성이 떨어지는 문제가 있었다. 동일한 패턴의 락 관리가 필요한 다른 비즈니스 로직이 있다면, 매번 이 코드를 복사하거나 유사하게 구현해야 했디.이러한 문제를 해결하기 위해 AOP(Aspect-Oriented Programming) 를 도입하여 분산락 로직을 비즈니스 로직으로부터 분리하고 추상화했다. DistributedLock이라는 커스텀 어노테이션을 정의하고, @Aspect를 사용하여 이 어노테이션이 붙은 메서드에 분산락 로직을 자동으로 적용하도록 구현했다.
DistributedLock 어노테이션
이 어노테이션은 락의 키(SpEL 지원), 대기 시간, 만료 시간, 공정 락 여부 등을 설정할 수 있도록 한다.@Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface DistributedLock { /** 단일 키(SpEL)를 지정합니다. keys()가 지정되면 무시됩니다. */ String key() default ""; /** 여러 키를 동시에 잠글 때 사용합니다 (SpEL 지원). 지정되면 key() 대신 이 값을 사용합니다. */ String[] keys() default {}; long waitTime() default 1; // 락을 획득하기 위해 대기할 시간 (단위: timeUnit) long leaseTime() default -1; // 락 유지 시간 (단위: timeUnit), -1은 watchdog 사용을 의미합니다. TimeUnit timeUnit() default TimeUnit.SECONDS; boolean fair() default false; // 공정 락(Fair Lock)을 사용할지 여부 }DistributedLockAspect (AOP 구현체)
이 애스펙트는 @DistributedLock 어노테이션이 붙은 메서드 실행 전후로 분산락을 획득하고 해제하는 로직을 담당한다. SpEL(Spring Expression Language)을 사용하여 메서드 인자로부터 동적으로 락 키를 생성하는 기능도 포함되어 유연성을 높였다.@Aspect @Order(Ordered.HIGHEST_PRECEDENCE) // 다른 AOP보다 먼저 실행되도록 우선순위 설정 @Component @RequiredArgsConstructor @Slf4j public class DistributedLockAspect { private final RedissonClient redissonClient; private final ExpressionParser parser = new SpelExpressionParser(); private final DefaultParameterNameDiscoverer nameDiscoverer = new DefaultParameterNameDiscoverer(); @Around("@annotation(distributedLock)") // @DistributedLock 어노테이션이 붙은 메서드에 적용 public Object lockAndProceed(ProceedingJoinPoint pjp, DistributedLock distributedLock) throws Throwable { MethodSignature msig = (MethodSignature) pjp.getSignature(); Method method = msig.getMethod(); DistributedLock lock = AnnotationUtils.findAnnotation(method, DistributedLock.class); if (lock == null) { return pjp.proceed(); // 어노테이션이 없으면 원래 메서드 실행 } // 1. 락 키 평가: keys()가 지정되면 여러 키 사용, 아니면 key() 사용 List<String> evaluatedKeys = new ArrayList<>(); if (lock.keys() != null && lock.keys().length > 0) { evaluatedKeys.addAll(parseKeys(lock.keys(), pjp)); } else { evaluatedKeys.add(parseKey(lock.key(), pjp)); } // 2. 락 키 정제: null, 공백 제거, 중복 제거, 정렬 (데드락 방지를 위해 전역 순서 고정) List<String> keys = evaluatedKeys.stream() .filter(k -> k != null && !k.isBlank()) .distinct() .sorted() // 멀티 락 시 데드락 방지를 위한 키 순서 정렬 .collect(Collectors.toList()); if (keys.isEmpty()) { log.warn("분산락 키가 비어있습니다. 메서드를 그대로 진행합니다. 메서드: {}", method.getName()); return pjp.proceed(); } // 락 파라미터 추출 long waitTime = lock.waitTime(); long leaseTime = lock.leaseTime(); TimeUnit timeUnit = lock.timeUnit(); boolean fairLock = lock.fair(); boolean acquired = false; RLock rLock = null; // 단일 락 또는 멀티 락 객체 if (keys.size() == 1) { // 단일 락 처리 String key = keys.get(0); rLock = fairLock ? redissonClient.getFairLock(key) : redissonClient.getLock(key); log.debug("단일 분산 락 시도: key={}", key); } else { // 멀티 락 처리 (RedissonMultiLock 사용) RLock[] rlocks = keys.stream() .map(k -> fairLock ? redissonClient.getFairLock(k) : redissonClient.getLock(k)) .toArray(RLock[]::new); rLock = new RedissonMultiLock(rlocks); log.debug("분산 멀티 락 시도: keys={}", keys); } try { // 락 획득 시도 (leaseTime에 따라 watchdog 또는 고정 lease 적용) acquired = (leaseTime < 0) ? rLock.tryLock(waitTime, timeUnit) : rLock.tryLock(waitTime, leaseTime, timeUnit); if (!acquired) { log.warn("분산락 획득 실패. key(s)={}", keys); return null; // 정책: 락 획득 실패 시 메서드 실행 스킵 // (필요하다면 throw new RuntimeException("락 획득 실패"); 로 변경 가능) } log.debug("분산락 획득 성공. key(s)={}", keys); return pjp.proceed(); // 락 획득 성공 시 비즈니스 로직 실행 } finally { // 락 해제 if (acquired && rLock.isHeldByCurrentThread()) { try { rLock.unlock(); log.debug("분산락 해제 완료. key(s)={}", keys); } catch (IllegalMonitorStateException e) { // 락이 이미 만료되어 해제되었을 경우 발생할 수 있는 예외 처리 log.warn("락이 이미 만료되었거나 다른 스레드에 의해 해제되었습니다. key(s)={}, 에러: {}", keys, e.getMessage()); } catch (Exception e) { log.error("락 해제 중 예상치 못한 오류 발생. key(s)={}", keys, e); } } } } // SpEL 키 파싱 도우미 메서드 (단일 키) private String parseKey(String spel, ProceedingJoinPoint pjp) { MethodSignature sig = (MethodSignature) pjp.getSignature(); String[] paramNames = nameDiscoverer.getParameterNames(sig.getMethod()); EvaluationContext ctx = new StandardEvaluationContext(); Object[] args = pjp.getArgs(); // 인덱스 기반 변수 (예: #p0, #a0) for (int i = 0; i < args.length; i++) { ctx.setVariable("p" + i, args[i]); ctx.setVariable("a" + i, args[i]); } // 이름 기반 변수 (예: #data) if (paramNames != null) { for (int i = 0; i < paramNames.length; i++) { ctx.setVariable(paramNames[i], args[i]); } } return parser.parseExpression(spel).getValue(ctx, String.class); } // SpEL 키 파싱 도우미 메서드 (여러 키) private List<String> parseKeys(String[] spels, ProceedingJoinPoint pjp) { if (spels == null || spels.length == 0) return Collections.emptyList(); List<String> out = new ArrayList<>(spels.length); for (String s : spels) { out.add(parseKey(s, pjp)); } return out; } }AOP 적용 후 비즈니스 로직
이제 DataProcessor는 락 관련 로직 없이 순수한 비즈니스 로직만 포함하게 된다. @DistributedLock 어노테이션 하나로 분산락을 쉽게 적용할 수 있다. 특히, keys 속성을 사용하여 여러 개의 락을 동시에 획득할 수 있도록 함으로써, 교착 상태 위험을 Redisson의 RedissonMultiLock과 락 키 정렬(sorted())로 관리할 수 있게 되었다.@Component @RequiredArgsConstructor @Slf4j public class DataProcessor { private final MainEntityRepository mainEntityRepository; private final DataRepository dataRepository; /** * 실제 데이터 처리 로직 (하나의 트랜잭션으로 묶임) * @DistributedLock 어노테이션으로 분산락을 선언적으로 적용합니다. */ @DistributedLock( keys = { "'lock:processing-target:' + #target.id", // 처리 대상 데이터 단위 락 "'lock:main-entity:' + #target.parentId" // 메인 엔티티 단위 락 }, waitTime = 1, // 락 획득을 위해 최대 1초 대기 leaseTime = -1 // 처리 시간이 가변적이므로 Redisson watchdog(자동 연장) 사용 ) @Transactional // DB 트랜잭션도 함께 적용됩니다. public void processSingleTarget(ProcessingTarget target) { if (target == null || target.getId() == null || target.getCreationTime() == null) { log.warn("필수 값이 없는 처리 대상 데이터입니다. 무시합니다. 데이터: {}", target); return; // 방어 로직: 필수 값 없으면 무시 } // 멱등성을 위한 추가 검증 (선택적) // AOP 밖에서 이미 처리된 항목인지 재확인 (다른 서버에서 락을 놓쳐 처리했을 가능성) if (Boolean.TRUE.equals(target.isProcessed())) { log.info("이미 처리된 데이터입니다. ID: {}", target.getId()); return; } // 핵심 비즈니스 로직 수행: // 예시: 메인 엔티티의 상태를 최신 데이터 기준으로 업데이트 mainEntityRepository.updateStatusByProcessingTarget( target.getParentId(), // 메인 엔티티 ID target.getCreationTime() ); // 처리 완료 플래그 업데이트 dataRepository.markAsProcessed(target.getId()); log.info("데이터 처리 완료. ID: {}, 부모 엔티티 ID: {}", target.getId(), target.getParentId()); } }데드락 발생 가능성 및 해결 (Redisson MultiLock) 위에서 구현된 AOP DistributedLockAspect는 멀티 락(Multi-Lock) 시 발생할 수 있는 교착 상태(Deadlock) 문제까지 고려하여 설계되었다.
만약 두 개의 락 (lock:A, lock:B)을 처리하는 트랜잭션이 있을 때,
트랜잭션 1: lock:A 획득 -> lock:B 획득 시도
트랜잭션 2: lock:B 획득 -> lock:A 획득 시도
위와 같은 순서로 락을 획득하려 하면 교착 상태가 발생할 수 있다. 이를 방지하기 위해 DistributedLockAspect는 두 가지 전략을 사용한다:
락 키 정렬 (.sorted()): 여러 개의 락 키를 대상으로 할 때, 락 획득 전에 모든 키를 알파벳 순서 등으로 정렬하여 항상 동일한 순서로 락을 획득하도록 강제한다. 예를 들어, lock:B와 lock:A를 동시에 획득하려 해도 lock:A를 먼저 시도하고 lock:B를 시도하게 하여, 락 순서를 통일시킨다.
RedissonMultiLock 활용: Redisson이 제공하는 RedissonMultiLock은 여러 개의 RLock 인스턴스를 하나의 논리적인 락으로 묶어 관리한다. RedissonMultiLock은 내부적으로 모든 락을 한 번에 획득하거나, 획득에 실패하면 획득했던 모든 락을 즉시 해제하는 방식으로 교착 상태를 회피하려는 노력을 한다. 이는 모든 락을 성공적으로 획득해야만 비즈니스 로직을 실행하는 원자성을 제공하여, 데드락 위험을 줄여준다.
따라서 keys 속성을 통해 여러 락을 지정하는 경우, 이 두 가지 메커니즘이 함께 작동하여 교착 상태를 예방하고 락의 안정성을 높인다.
💡눈치가 빠르신 분들은 눈치 채셨겠지만, 위 코드에는 배치로 미리 값을 가져오기 때문에, 다른 워커쓰레드가 처리한 데이터라도 메모리 상으로는 처리가 안됐다고 생각해 재처리하는 문제가 발생할 수 있습니다. 다중 처리 서버에서 서버간 데이터 접근에 대한 동시성 제어와 데이터 정합성은 보장하지만, 위 문제로 인해 병렬처리 성능은 떨어집니다. 위왁 같은 유스케이스에서는 분산락 대신(또는 함께) 메시지 큐를 도입하는 것이 모범사례라는 것을 인지해주시기 바랍니다.
Redis 분산락의 한계
Redis 기반 락에도 단점은 존재한다. 특히, 다중 노드 기반 RedLock 알고리즘에서는 다음과 같은 문제가 발생할 수 있다:
- 각 Redis 노드의 Clock Drift로 인해 TTL 판단이 엇갈릴 수 있음
- 과반수 기준의 TTL 해제 시점이 엇갈리면 동일 자원에 두 클라이언트가 동시에 락을 가진 상태 발생 가능
예시:
- 클라이언트 A가 A, B, C에서 락 획득 → 과반수 만족
- TTL 만료 전, A가 먼저 락 해제되고 C는 여전히 유지 중
- 클라이언트 B가 C, D, E에서 락 획득
- C에서는 여전히 A의 락 유효 → 동일 자원에 중복 락 발생
이러한 문제는 실제로 드물지만, 실무에서는 DB 수준의 멱등성 검증 로직이 반드시 필요하다. 조건부 UPDATE/INSERT 등을 통해 동일 요청이 여러 번 처리되지 않도록 방지하는 구조가 안전하다.
마무리하며
- Redisson은 락 관련 복잡한 구현 없이 분산 환경에서도 간편하게 락을 사용할 수 있다.
RLock은 pub/sub 기반으로 효율적인 대기와 자동 해제 기능까지 포함된 고수준 API이다.- 그러나 락만으로는 부족하며, 최종 자원 처리에선 항상 멱등성을 보장해야 한다.