자료형과 기능

📕 레디스 스터디 시리즈
이번 포스팅에서는 대표적인 보조 자료형과 기능, 그리고 보조 자료형과 관련된 명령어에 대해 정리해보겠습니다.
대표 기능과 관련 명령어
비트맵(비트 배열)
현재 처리하고 있는 데이터 모델을 비트의 존재 여부나 그 위치에 따라 표현하여 메모리를 절약할 수 있습니다.
예시
각 비트의 위치를 사용자 ID와 연결한 후 그 위치가 1 또는 0인지 값을 확인하여 특정 기능의 사용 여부 등을 사용자 별로 관리할 수 있습니다.
예를 들어, "알림 받기" 기능을 사용자별로 관리하고 싶다고 해봅시다. 위 그림에서 0은 알림을 끈 상태, 1은 알림을 킨 상태를 나타냅니다. 2번 유저, 101번 유저, 103번 유저, 999번 유저는 "알림 받기" 기능을 켰다고 볼 수 있겠네요. 총 2^32개의 유저까지 표현할 수 있습니다.
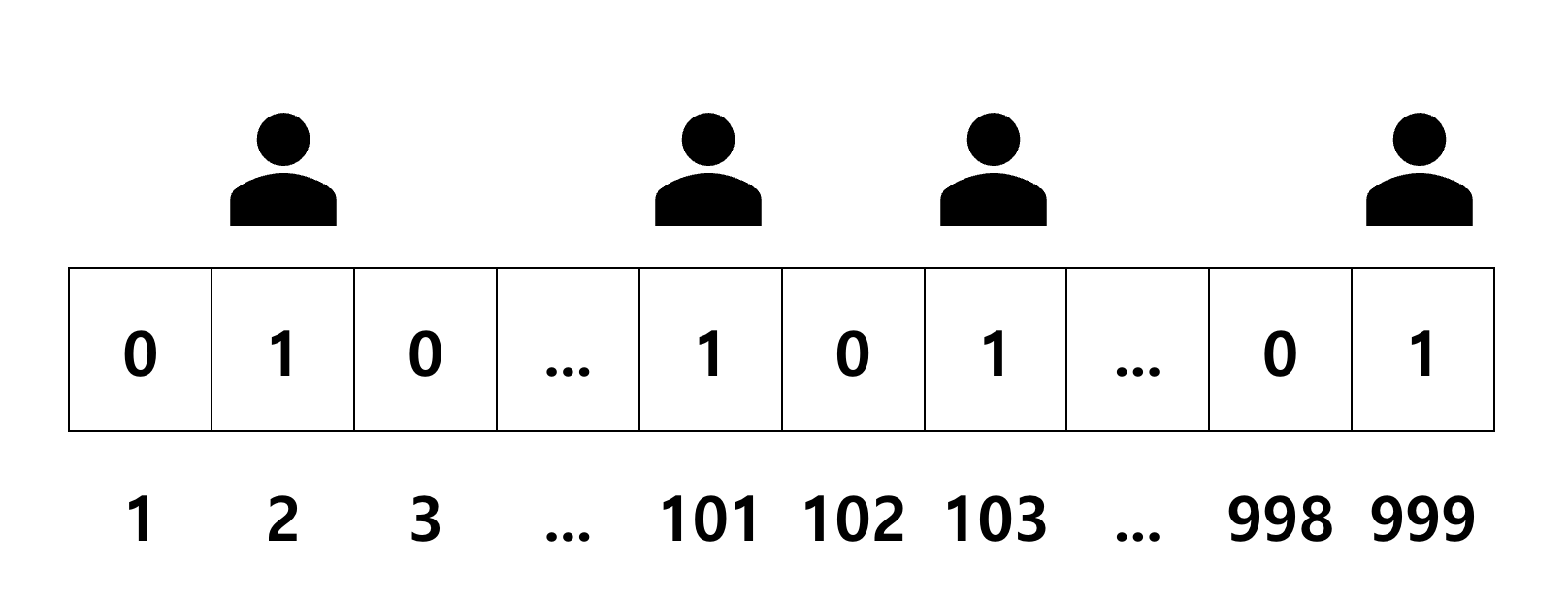
⚠️비트맵이 희소한 상태(대부분이 0인 상태)인 경우는, 메모리를 비효율적으로 사용한다는 의미이므로, Set형을 고려하는 것이 좋습니다.
비트맵 동작 예시는 다음과 같습니다.
127.0.0.1:6379> SETBIT mybit 100 1 (integer) 1 127.0.0.1:6379> GETBIT mybit 100 (integer) 1 127.0.0.1:6379> GETBIT mybit 101 (integer) 0비트맵도 마찬가지로 string 형으로 취급합니다.
127.0.0.1:6379> TYPE mybit string
비트맵 자료형에 대한 자주 사용하는 명령어 목록은 다음과 같습니다:
| 명령어 | 용도 | 사용 예시 |
|---|---|---|
| GETBIT | 지정한 offset의 비트 값을 반환함 (0 또는 1) | GETBIT mybit 100 |
| SETBIT | 지정한 offset의 비트를 0 또는 1로 설정하고, 이전 값을 반환함 | SETBIT mybit 100 1 |
| BITCOUNT | 지정한 문자열(비트맵)에서 1로 설정된 비트의 개수를 반환함 | BITCOUNT mybit |
| BITOP | 여러 비트맵 간 비트 연산(AND, OR, XOR, NOT)을 수행하고 결과를 저장함 | BITOP AND result key1 key2 |
| BITPOS | 지정한 값(0 또는 1)이 처음 등장하는 비트의 위치(offset)를 반환함 | BITPOS mybit 1 |
| BITFIELD | 비트 필드를 여러 개의 정수로 해석하고, 증감 연산 등을 수행함 | BITFIELD mybit INCRBY i5 100 1 |
| BITFIELD_RO | 읽기 전용 비트 필드 연산. 비트 값을 정수로 해석해서 반환하지만 수정은 하지 않음 | BITFIELD_RO mybit GET i8 0 |
비트 타입 지정
i5: 부호 있는 정수, 5비트 크기 (-16 ~ 15)i8: 부호 있는 정수, 8비트 크기 (-128 ~ 127)u8: 부호 없는 정수, 8비트 크기 (0 ~ 255)
_RO의 의미
- Read-Only 전용 명령어
- 쓰기 오버헤드 없음, AOF/복제 로그 기록 불필요
- Replica에서도 실행 가능
지리적 공간 인덱스
지리적 공간 정보는 주소나 경도/위도 등 지구상 지리적 위치 정보를 나타냅니다.
레디스는 각 위치 정보를 경도/위도의 2차원 지리적 공간 정보 인덱스로서 GeoHash를 사용할 수 있습니다.
GeoHash는 경도/위도 두 개의 좌표를 하나의 문자열로 합친 것으로, 그리드 내의 영역을 표시합니다.
지리적 공간 인덱스는 내부적으로 Sorted Set형으로 키가 저장되어 있습니다.
💡 GeoHash
- GeoHash는 위도/경도를 비트로 변환하여 문자열로 인코딩한 값이다.
- 문자열이 길어질수록 정밀도는 높아지고, 더 작은 지역(좁은 그리드)을 나타낸다.
- 문자열이 짧아질수록 정밀도는 낮아지고, 더 큰 지역(넓은 영역)을 포괄한다.
- 예:
wx4g→ 베이징 근처의 큰 사각형,wx4g09→ 훨씬 더 작은 영역.
지리적 공간 인덱스 활용 예시는 다음과 같습니다.
127.0.0.1:6379> GEOADD places 127.0817 37.4981 "Gangnam" (integer) 1 127.0.0.1:6379> GEOADD places 126.9780 37.5665 "SeoulStation" (integer) 1 127.0.0.1:6379> GEODIST places Gangnam SeoulStation km "7.5" 127.0.0.1:6379> GEORADIUS places 127 37 10 km 1) "Gangnam" 2) "SeoulStation" 127.0.0.1:6379> GEOHASH places "Gangnam" 1) "wydmuvn2h10"
| 명령어 | 용도 | 사용 예시 |
|---|---|---|
| GEOADD | 위도/경도 좌표와 이름을 지정하여 지리적 위치를 추가함 | GEOADD places 127.0817 37.4981 "Gangnam" |
| GEOHASH | 지정한 멤버의 좌표를 GeoHash 문자열로 반환함 | GEOHASH places "Gangnam" |
| GEOPOS | 지정한 멤버의 위도/경도 좌표를 반환함 | GEOPOS places "Gangnam" |
| GEODIST | 두 위치 간의 거리를 반환함 (단위: m, km, mi, ft) | GEODIST places Gangnam SeoulStation km |
| GEOSEARCH | 지정한 중심 좌표나 멤버 기준으로 반경/박스 내의 위치들을 검색함 | GEOSEARCH places FROMLONLAT 127 37 BYRADIUS 10 km |
| GEOSEARCHSTORE | GEOSEARCH 결과를 새로운 키에 저장함 | GEOSEARCHSTORE nearby places FROMLONLAT 127 37 BYRADIUS 10 km |
Pub/Sub 기능
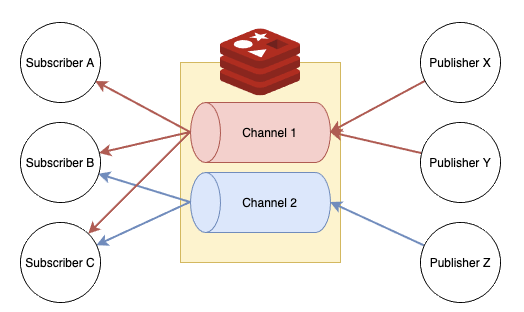
Pub/Sub 모델은 발신자인 발행자(Publisher)가 수신자인 구독자(Consumer)에게 정보를 저장하지 않고 메시지를 보내는 패턴을 의미합니다.
레디스에서 Pub/Sub은 자료형이 아닌 기능 형태로 제공합니다.
구독자는 관심 있는 주제에 대해 하나 이상의 채널을 구독할 수 있습니다. 발행자는 특정 채널을 지정하여 이 채널을 통해 메시지를 발행합니다. 발행자가 발행한 메시지는 해당 채널을 구독하고 있는 모든 구독자가 메시지 형태로 받아볼 수 있습니다.
⭐️Kafka와 어떤 점이 다른가요?
- 메시지 저장 여부: Redis Pub/Sub은 메시지를 저장하지 않고 즉시 전달, Kafka는 로그에 영구 저장 후 소비자가 읽음.
- 소비 모델: Redis는 실시간 브로드캐스트 방식, Kafka는 Consumer Group을 통한 개별 오프셋 기반 소비.
- 확장성: Redis는 단순 구조로 소규모 실시간 알림에 적합, Kafka는 파티션 기반으로 대규모 데이터 스트리밍에 최적화.
- 메시지 유실 및 재처리: Redis Pub/Sub은 구독자가 연결되어 있지 않으면 메시지가 유실되고, 재처리 기능이 없다. Kafka는 메시지를 로그에 저장하므로 소비자가 나중에 다시 읽을 수 있고, 재처리 및 리플레이가 가능하다.
📕At most once이며,ack도 없다.
Pub/Sub에서 사용 가능한 레디스 명령어는 다음과 같습니다:
| 명령어 | 용도 | 사용 예시 |
|---|---|---|
| PUBLISH | 특정 채널에 메시지를 발행함 | PUBLISH news "hello" |
| SUBSCRIBE | 하나 이상의 채널을 구독함 | SUBSCRIBE news sports |
| UNSUBSCRIBE | 현재 구독 중인 하나 이상의 채널 구독을 취소함 | UNSUBSCRIBE news |
| PSUBSCRIBE | 패턴 기반으로 채널들을 구독함 (news.* 등) |
PSUBSCRIBE news.* |
| PUNSUBSCRIBE | 패턴 기반으로 구독 중인 채널들을 구독 해제함 | PUNSUBSCRIBE news.* |
| SPUBLISH | Sharded Pub/Sub에서 특정 shard 채널에 메시지를 발행함 | SPUBLISH tech "update" |
| SSUBSCRIBE | Sharded Pub/Sub에서 특정 shard 채널을 구독함 | SSUBSCRIBE tech |
| SUNSUBSCRIBE | Sharded Pub/Sub에서 특정 shard 채널의 구독을 취소함 | SUNSUBSCRIBE tech |
| PUBSUB | 현재 Pub/Sub 상태를 조회함 (예: 구독자 수, 채널 목록) | PUBSUB CHANNELS |
⛔️Redis의 Pub/Sub은 "핫 퍼블리셔"로 동작해요.
Redis의 Pub/Sub 기능은 핫 퍼블리셔로 동작하기 때문에, 발행 도중에 구독한 구독자는 구독 이전 시점의 메시지를 받을 수 없습니다.
Sharded Pub/Sub 기능
레디스 7.0 미만에서는 노드에 발행된 메시지가 다른 모든 노드에 전달(브로드 캐스팅)되므로 클러스터 버스의 버퍼 관리로 인해 메인 스레드 CPU 부하가 높아질 수 있었습니다. 이 문제를 해결하기 위해 레디스 7.0에서 Sharded Pub/Sub 기능이 도입되었습니다.
이름에서 알 수 있듯, 모든 노드에 메시지를 전달하는 대신, 채널 자체를 하나의 슬롯에 매핑하여, 해당 슬롯을 보유한 샤드(마스터 노드 + 레플리카 노드)에 구독한 구독자들에게만 메시지를 전달하여 부하를 낮추고 트래픽 병목을 해결했습니다.
자주 사용되는 명령어는 다음과 같습니다:
| 명령어 | 용도 | 사용 예시 |
|---|---|---|
| SPUBLISH | Sharded Pub/Sub에서 메시지를 발행함 | SPUBLISH sports "goal!" |
| SSUBSCRIBE | Sharded Pub/Sub 채널을 구독함 | SSUBSCRIBE sports |
| SUNSUBSCRIBE | Sharded Pub/Sub 채널 구독을 해제함 | SUNSUBSCRIBE sports |
HyperLogLog
HyperLogLog는 고유한 수를 효과적으로 계산할 수 있는 확률적 계산 방법입니다.
오차가 다소 있지만, 메모리 공간을 효율적으로 사용할 수 있다는 장점이 커서, 정확한 값을 알 필요가 없는 상황에 사용됩니다.
🦑 HyperLogLog의 숫자 산출방식은 다음과 같은 단계로 이루어집니다:
- 해시(Hash) 처리: 입력된 각 원소를 해시 함수에 넣어 고르게 분포된 비트열을 생성합니다.
- 선행 0 개수 계산: 해시 결과의 비트열에서 가장 앞쪽부터 연속된 0의 개수를 셉니다.
- 레지스터(Register) 저장: 각 해시값을 특정 레지스터에 매핑하고, 해당 레지스터에 지금까지 관찰된 최대 선행 0 개수를 저장합니다.
- 조화평균 기반 추정: 모든 레지스터 값들을 조화평균으로 계산하여 전체 원소의 고유 개수를 추정합니다.
- 보정 단계: 작은 집합이나 매우 큰 집합에 대해 오차를 줄이기 위해 보정 알고리즘을 적용합니다.
이 과정을 통해 HyperLogLog는 매우 적은 메모리로 대규모 데이터의 고유 개수를 근사하여 계산할 수 있습니다.
| 명령어 | 용도 | 사용 예시 |
|---|---|---|
| PFADD | HyperLogLog에 요소 추가 | PFADD uv:2025 user1 user2 |
| PFCOUNT | 고유 개수 추정값 반환 | PFCOUNT uv:2025 |
| PFMERGE | 여러 HLL을 합쳐 새로운 HLL 생성 | PFMERGE uv:week uv:mon uv:tue |
| PFDEBUG | 내부 상태 확인(디버그용) | PFDEBUG GETREG uv:2025 |
Redis Stream
레디스 스트림은 스트림 작업에 사용되는 기능입니다. 레디스 5.0 이후에 추가된 기능입니다.
다음과 같은 요구사항이 있다면 고려할 법 합니다:
- 데이터가 연속으로 대량 발생하는 상황에서 기존 데이터 변경 없이 추가하는 경우
- 구조화된 데이터를 핸들링하는 경우
- 과거 데이터를 유지해야 하는 경우(Pub/Sub과의 가장 큰 차이점입니다)
Redis Stream은 Kafka와 비슷하게 소비자를 Consumer Group으로 묶을 수 있으며, 소비하려는 메시지를 ACK하는 특성을 지닙니다.
소비자가 처리하기로 결정한 엔트리(각 메시지/이벤트)는 Redis 내에 PEL 저장소에 관리됩니다. 소비자의 오류 등으로 인헤 메시지가 처리가 되지 않았다고 해도, PEL의 내용이 자동으로(시간 경가에 의해) 다른 소비자에게 가는 상황은 없습니다.
그래서 해당 엔트리의 소유권을 다른 소비자에게 넘겨주어 처리하기 위해 XCLAIM, XAUTOCLAIM같은 명령어들이 존재합니다.
다음은 Redis Stream의 주요 명령어 입니다:
| 명령어 | 용도 | 사용 예시 |
|---|---|---|
| XADD | 스트림에 새 항목을 추가함 | XADD mystream * field1 value1 |
| XRANGE | 스트림 내 특정 범위의 항목들을 오름차순으로 조회함 | XRANGE mystream - + |
| XREVRANGE | 스트림 내 특정 범위의 항목들을 내림차순으로 조회함 | XREVRANGE mystream + - |
| XREAD | 하나 이상의 스트림에서 새 항목을 읽음 | XREAD COUNT 2 STREAMS mystream 0 |
| XLEN | 스트림에 저장된 항목의 총 개수를 반환함 | XLEN mystream |
| XDEL | 스트림에서 특정 항목들을 삭제함 | XDEL mystream 1526985058136-0 |
| XTRIM | 스트림의 길이를 제한하여 오래된 항목들을 제거함 | XTRIM mystream MAXLEN 1000 |
| XINFO | 스트림 또는 소비자 그룹에 대한 메타정보를 조회함 | XINFO STREAM mystream |
| XGROUP | 소비자 그룹을 생성하거나 관리함 | XGROUP CREATE mystream mygroup 0 |
| XREADGROUP | 소비자 그룹의 멤버가 스트림 항목을 읽음 | XREADGROUP GROUP mygroup Alice STREAMS mystream > |
| XACK | 소비자 그룹에서 처리 완료한 메시지에 대해 확인 응답함 | XACK mystream mygroup 1526985058136-0 |
| XCLAIM | 소비자 그룹에서 메시지 소유권을 다른 소비자로 이전함 | XCLAIM mystream mygroup Alice 60000 1526985058136-0 |
| XPENDING | 소비자 그룹의 처리 대기 중인 메시지 상태를 조회함 | XPENDING mystream mygroup |
| XAUTOCLAIM | 지정한 시간 이상 처리되지 않은 메시지를 자동으로 재할당함 | XAUTOCLAIM mystream mygroup Alice 60000 0-0 |
Redis Stream vs Kafka 비교
| 구분 | Redis Stream | Kafka |
|---|---|---|
| 데이터 저장 방식 | 메모리에 저장, RDB/AOF로 영속화 가능 | 디스크 로그 세그먼트에 순차 기록, 영구 저장 가능 |
| 메시지 보존 | 기본 무제한 저장, XTRIM으로 수동/자동 삭제 가능 |
토픽 단위로 보존 기간/크기 정책 설정 |
| 소비자 모델 | Consumer Group 기반, ack 후 메시지 확인 완료 | Consumer Group 기반, 오프셋(offset) 추적 |
| 확장성 | 단일 인스턴스 한계 → 샤딩/클러스터링 필요 | 파티션 단위 확장에 최적화, 대규모 스트리밍에 강함 |
| 재처리/리플레이 | XRANGE, XREADGROUP으로 과거 메시지 재조회 가능 |
오프셋을 조정해 과거 메시지 재처리 가능 |
| 파티션/키 라우팅 | 내장 파티션 없음. 필요하면 앱 레벨에서 events:0..N-1로 스트림 파티셔닝(예: hash(id)%N)을 구성 |
내장 파티션 있음. key 기반 파티셔닝으로 같은 key를 항상 같은 파티션에 라우팅 |
| 순서 보장 범위 | 저장 순서(ID)는 전역 유지. 처리 순서는 그룹 분산/재할당(XCLAIM/XAUTOCLAIM)로 깨질 수 있음 | 파티션 내에서만 순서 보장. 같은 key ⇒ 같은 파티션일 때 브로커 저장·전달 순서가 보존됨 |
| 처리 순서 조건 | 키별 직렬성은 애플리케이션이 보장해야 함: 스트림 파티셔닝, Actor/디스패처, 멱등+버전 체크 등 | 프로듀서 idempotence 활성화(enable.idempotence=true), max.in.flight=1, 컨슈머는 파티션당 순차 처리 |
| 장애/재할당 영향 | 재할당/재시도 시 후착 메시지 선처리 가능 → 처리 순서 역전 위험. 운영 정책으로 완화 필요 | 리밸런스로 파티션 소유자가 바뀌어도 파티션 순서 자체는 유지. 다만 컨슈머가 병렬 처리하면 부작용 순서는 어긋날 수 있음 |