카프카 설치하기

🔍 카프카 스터디 시리즈
⭐️ 이번 2장의 제목은 '카프카 설치하기' 이지만, 설치 방법에 대해서는 따로 다룰 가치를 느끼지 못하겠으므로 카프카 컨트롤러 노드, 메타데이터 관리, 브로커 및 컨슈머 설정 등에 대해 다루도록 하겠습니다.
Zookeeper vs KRaft
앞서 Chap1. 카프카 시작하기 에서는 Kafka가 Zookeeper 방식과 KRaft 방식으로 동작한다고 KIP-500에 대한 이야기를 포함하여 설명하였습니다.
이번 절에서는 Zookeeper, KRaft가 필요한 이유와 왜 카프카 커뮤니티가 KRaft라는 대안을 선택하게 되었는지에 대해 간략하게 알아보고자 합니다.
Kafka 메타데이터 관리의 중요성
Kafka는 단순한 메시지 큐가 아닙니다. Kafka의 본질은 분산 로그 시스템이고, 분산 시스템에서 사장 어려운 문제는 데이터가 아니라 상태(state)입니다.
Kafka에서 말하는 메타데이터는 source of truth로 관리되어야 합니다:
- 이 토픽은 몇 개의 파티션으로 구성되어 있는가
- 각 파티션의 리더 브로커는 누구인가
- 팔로워는 누구이며, ISR(In-Sync Replica)는 무엇인가
- 지금 이 클러스터의 컨트롤러는 누구인가
Kafka 클러스터에서는 수많은 브로커가 동시에 동작하므로, 각 브로커는 네트워크 지연, GC, 장애 등으로 언제든 뒤쳐질 수 있습니다.
이 상태에서 각 프로커가 각자 판단으로 리더를 정하거나 파티션 상태를 관리한다면, 클리스터는 즉시 split brain 상태가 될 것입니다.
그래서 Kafka에는 다음이 필요했습니다:
- 전역적으로 일관된 메타데이터
- 단일 컨트롤러에 의한 결정
- 장애시에도 빠르게 복구 가능한 선출 메커니즘
이 문제를 외부에서 해결해주던 존재가 바로 Apache ZooKeeper 였습니다.
ZooKeeper 등장 배경
![]()
Kafka가 처음 설계되던 시점에서, 다음 문제를 직접 구현하는 일은 너무나 리스크가 컸습니다:
- 분산 화경에서의 리더 선출
- 장애 감지
- 메타데이터의 강한 일관성 보장
- 네트워크 분할 상황에서의 안전성
그래서 링크드인의 카프카 개발자들은 이 문제를 미리 해결한 시스템인 ZooKeeper를 사용하기로 결정했습니다.
ZooKeeper는 '분산 코디네이션 서비스'라는 다소 추상적인 이름을 갖고 있지만, 실제로는 다음에 특화되어 있습니다:
- 소수의 메타데이터를 강한 일관성으로 저장
- 변경 사항을 원자적으로 브로드캐스트
- 리더 기반 합의 구조 제공
그래서 Kafka 브로커와 ZooKeeper는 아래와 같은 역할을 맡게 되었습니다.
| 구분 | 주요 역할 |
|---|---|
| Kafka 브로커 | • 실제 메시지 로그 저장 • 프로듀서/컨슈머 요청 처리 |
| ZooKeeper | • 브로커 목록 관리 • 토픽/파티션 메타데이터 저장 • 컨트롤러 선출 |
이러한 상황에서, Kafka는 빠르게 성장할 수 있었지만, 기술부채를 쌓게 되었습니다.
- Kafka와 ZooKeeper라는 이중 분산 시스템
- 장애 시 Kafka 문제인지 ZooKeeper 문제인지 알기 어려움
- 운영자가 Kafka를 쓰기 위해 ZooKeeper 내부까지 이해해야 하는 구조
ZooKeeper 아키텍처
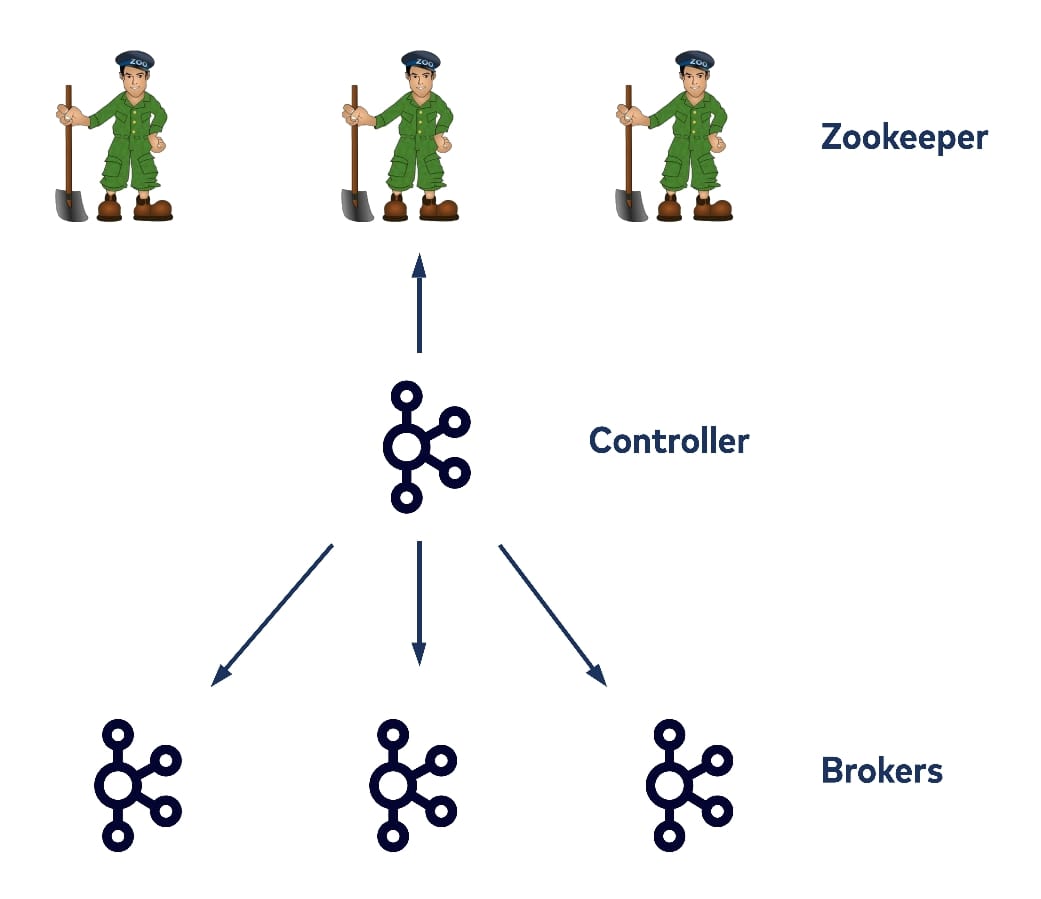
ZooKeeper 기반 Kafka에서는 단일 브로커가 컨트롤러로 선출되며, 컨트롤러는 파티션 리더 선출, ISR 변경, 토픽 메타데이터 변경과 같은 결정(decision) 을 수행하고 그 결과를 ZooKeeper에 기록합니다.
메타데이터 쓰기(write)는 주로 컨트롤러에서 발생하지만, 다른 브로커들도 ZooKeeper에 직접 접근하여 자신과 관련된 메타데이터를 read 및 watch할 수 있습니다.
이로 인해 메타데이터 변경 시 ZooKeeper를 중심으로 대규모 watch 이벤트 fan-out이 발생하며, 파티션 수와 브로커 수가 증가할수록 컨트롤러 및 ZooKeeper 모두에서 확장성 문제가 나타나게 됩니다.
이러한 구조적 한계는 컨트롤러의 단일화 때문 뿐이 아니라, 메타데이터 전파가 ZooKeeper 기반 watch 메커니즘에 의존했기 때문입니다.
KRaft 아키텍처
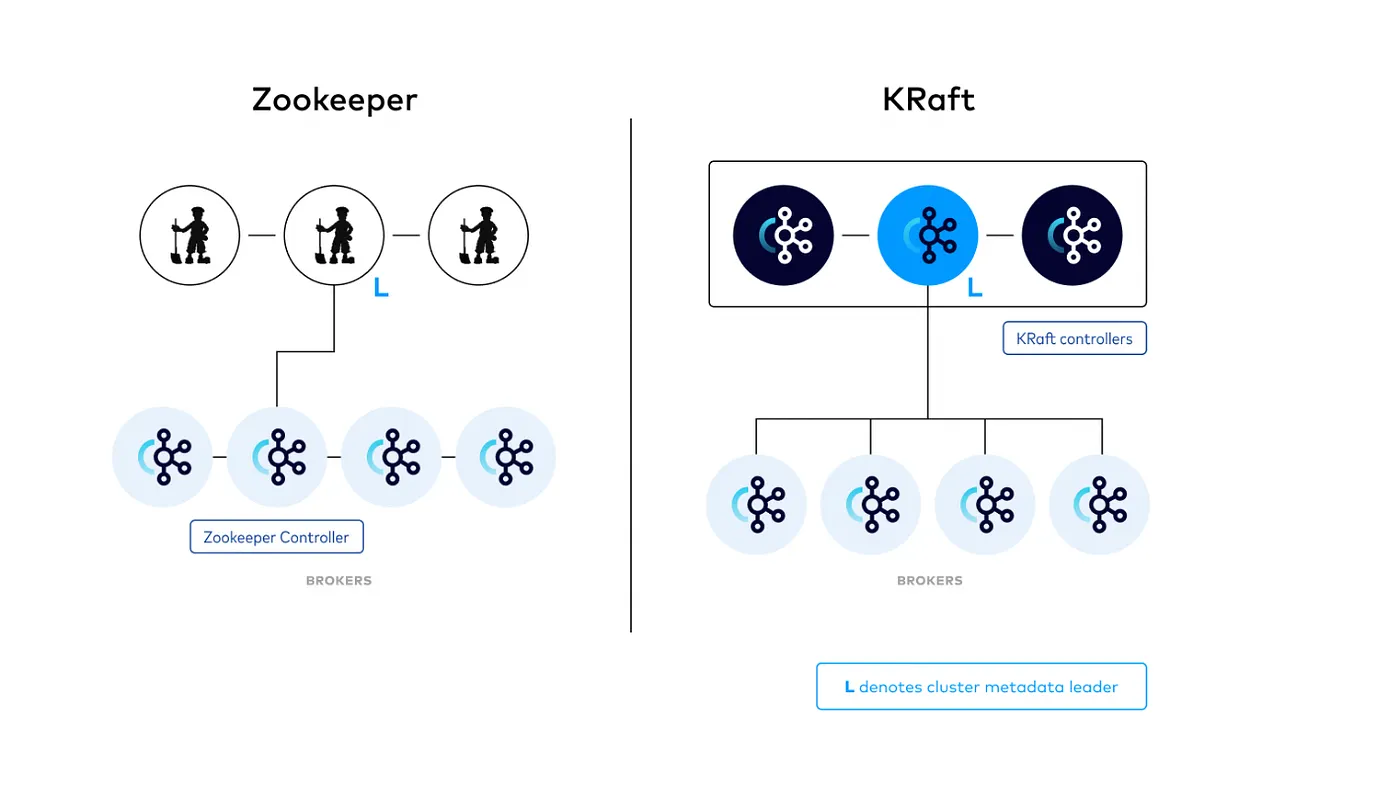
KRaft는 ZooKeeper와 달리 단일 컨트롤러가 아닌 Quorum Controller라 불리는 Broker 다수(클러스터)로 구성됩니다.
앞으로는 이 Quorum Controller 들을 컨트롤러라고 줄여부르겠습니다.
이 컨트롤러들은 모두가 같은 권리를 가지는 것이 아니라, 컨트롤러 안에서도 Raft Leader와 Raft Follower 라는 두 계층으로 나뉘게 됩니다.
메타데이터 변경은 모두 append-only 로그로 기록되며, Leader만이 로그를 append 할 수 있습니다. 나머지 Follower들은 이를 복제합니다.
또한 Leader 장애시 Follower 들은 리더 선거에 참여하고 커밋 여부를 판단하는 역할도 합니다.
Zookeeper 기반 아키텍처에서는 결정과 합의가 분리되어있었는데요, 'Kafka 컨트롤러가 결정하고, ZooKeeper가 합의'하는 구조였습니다.
KRaft에서는 이 결정화 합의가 모두 Kafka 내부에서 로그 기반으로 이루어지게 됩니다.