Spring Batch 성능 개선기 - N+1 문제
1. 서론
| 알림 발송 시스템 | 추천 전처리 시스템 |
|---|---|
 |
 |
본 문서에서 다루는 배치 애플리케이션(추천 전처리 시스템)은 단순한 통계 집계가 아닌, 실제 서비스에서 사용자의 시청 이력에 기반한 개인화 푸시 알림을 빠르게 발송하기 위한 전처리 역할을 합니다. 서비스 입장에서는 수십만 명의 사용자에게 5분 이내로 추천 알림을 보내야 하고, 알림을 받은 사용자가 앱을 열었을 때 곧바로 추천 콘텐츠를 확인할 수 있어야 합니다.
하지만 알림 발송 시점마다 추천 로직을 실시간으로 실행한다면 문제가 생깁니다. 데이터베이스 I/O와 연산 비용으로 대규모 트래픽을 감당하기 어렵고, 지연도 불가피해집니다.
운영 환경에서는 마케터나 관리자들이 캠페인을 구성한 후, 특정 시간 예약 발송이나 즉시 발송을 유동적으로 선택합니다. 발송 요청 시점에야 "어느 사용자의 추천 데이터가 필요한지"가 드러나므로, 사전 계산 전략만으로는 부족합니다. 따라서 예약/즉시 여부와 무관하게 언제든 빠른 알림을 위해, 매일 자정에 모든 활성 사용자에 대한 다음 추천 후보를 미리 계산하는 전처리 배치가 필수입니다.
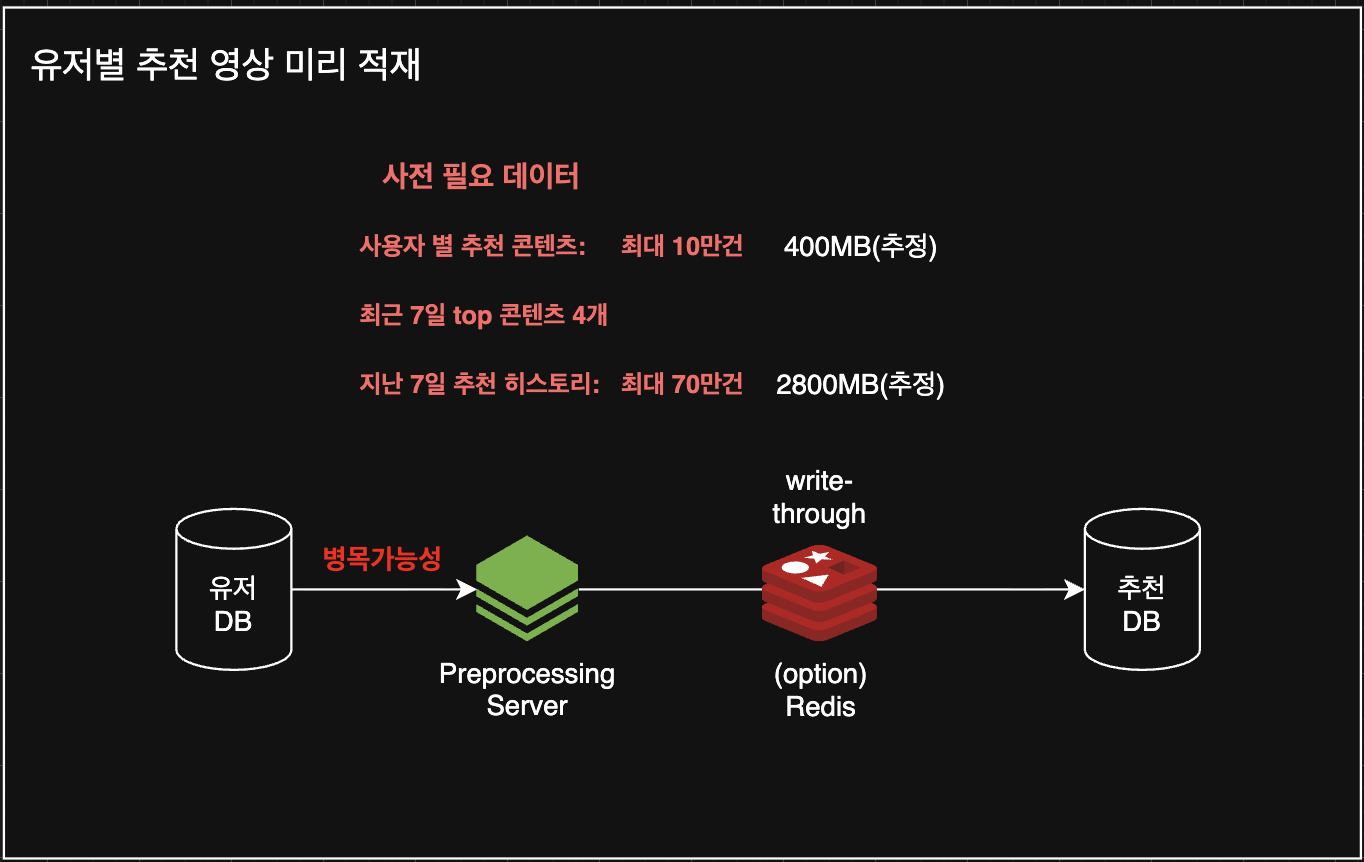
이를 위해 전체 알림 파이프라인을 두 단계로 분리했습니다. 첫 번째 단계는 본 문서의 주제인 전처리 배치(preprocessing) 입니다. 매일 자정에 사용자의 시청 이력과 최근 추천 이력을 분석해 "지금 보내도 좋은" 후보 콘텐츠를 추천 DB(및 Redis)에 적재합니다. 이 서버는 AWS EventBridge 스케줄러에 의해 EC2 인스턴스가 기동될 때 실행되며, 처리 시간이 길어질수록 알림 지연과 인프라 비용이 증가합니다. 따라서 배치 성능 개선은 서비스 품질과 비용 최적화를 위한 핵심 과제입니다.
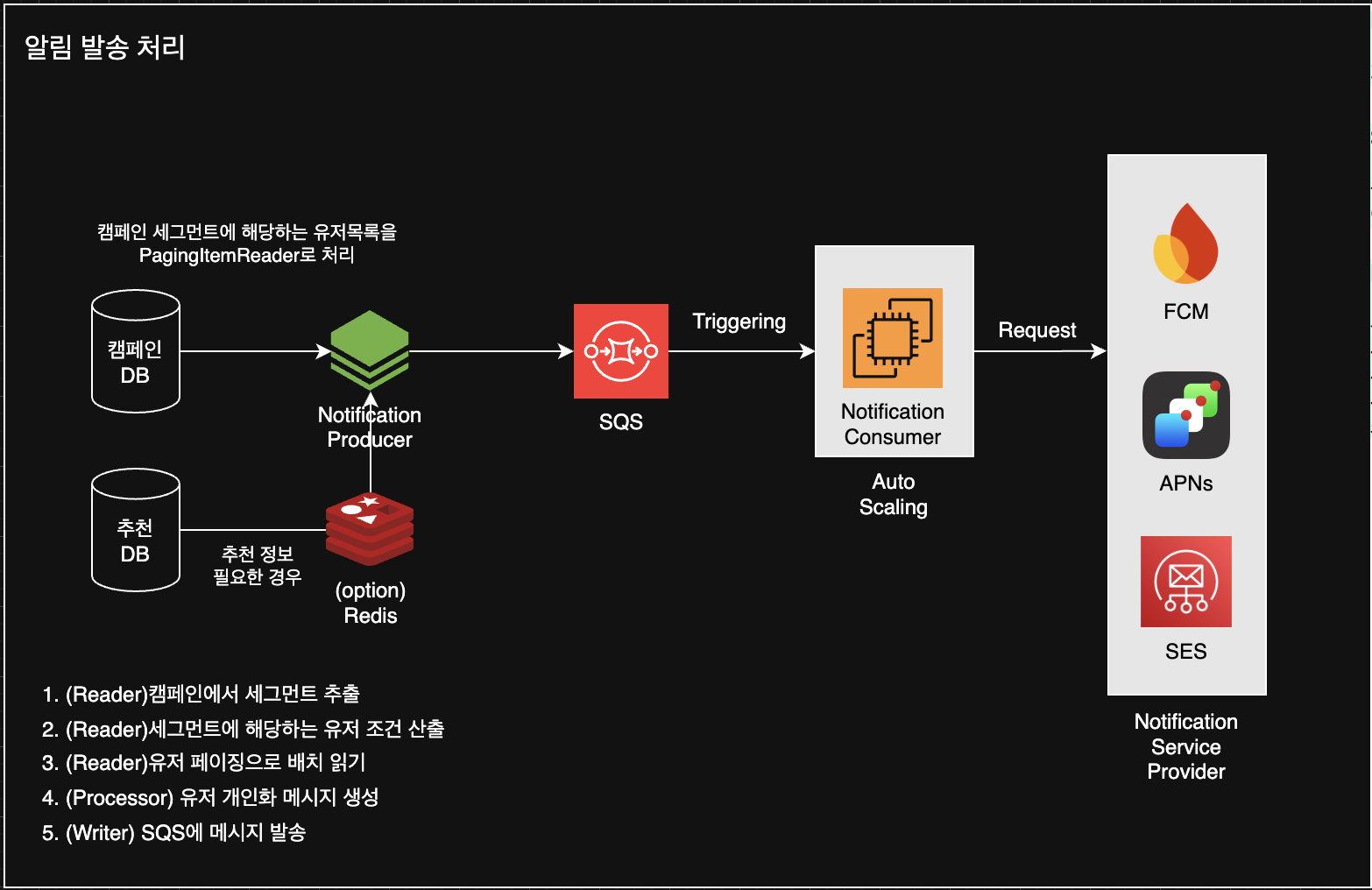
두 번째 단계는 알림 배치(notification batch) 입니다. 캠페인 세그먼트 사용자 목록을 조회해 전처리 결과를 읽고 SQS에 메시지를 적재한 후, 오토 스케일링되는 Notification Consumer가 FCM/APNs/SES로 알림을 발송합니다.
아키텍처적으로 전처리 배치는 파이프라인의 무거운 연산 레이어입니다. 전체 흐름은 다음 두 다이어그램으로 요약됩니다:
- 캠페인 배치가 SQS를 통해 Notification Consumer를 트리거하고 실제 알림을 발송하는 흐름.
- 개인화 추천 전처리 배치가 유저 DB를 읽어 추천 DB에 결과를 적재하는 흐름.
이 글에서는 2.의 전처리 배치 성능 개선 과정을 중점적으로 다루며, Reader/Processor/Writer 구조에서 발생한 N+1 쿼리 문제를 어떻게 해결했는지, 그리고 그 과정에서 발견된 추가 병목을 어떻게 극복했는지 스토리텔링 형식으로 설명하겠습니다.
2. Spring Batch의 기본 구조: Reader, Processor, Writer
Spring Batch의 핵심은 Read-Process-Write(RPW) 아키텍처입니다. 본 배치에서 각 컴포넌트의 역할은 다음과 같습니다.
-
Reader (
MemberWithHistoriesReader/MemberDataReader):
데이터 소스에서 회원 정보, 시청 이력, 최근 추천 이력을 페이지 단위로 조회해MemberProcessDto객체로 조합하여 Processor에 전달합니다. N+1 문제를 피하기 위해 필요한 데이터를 미리 일괄 로딩합니다. -
Processor (
PersonalizedRecommendationProcessor):
MemberProcessDto를 기반으로 개인화 추천을 수행합니다. 시청 이력이 없으면 전역 인기 미디어, 있으면 선호 장르/메뉴/채널 기반으로 추천하며, 최근 7일 추천 미디어를 제외합니다. 메모리 내 로직으로PersonalizedRecommendationEntity를 생성해 Writer에 전달합니다. -
Writer (
PersonalizedRecommendationWriter):
청크 단위로PersonalizedRecommendationEntity를recommendation_results_table에 대량 삽입합니다.JdbcBatchItemWriter를 사용해 효율적 쓰기를 구현합니다.
다음 다이어그램은 이 컴포넌트 간 데이터 흐름을 보여줍니다.
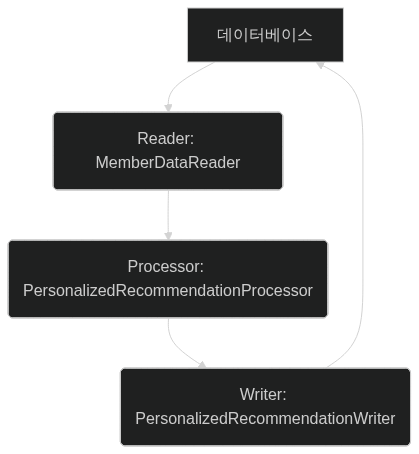
이 구조는 청크 단위 처리로 효율성을 추구하지만, 데이터베이스 I/O가 병목이 될 수 있습니다. 초기 구현에서 Reader와 Processor의 N+1 쿼리가 주요 문제로 드러났습니다.
3. 문제 발견: N+1 쿼리로 인한 I/O 병목
3.1. 배치 처리의 병목 요소
배치 성능 저하의 주범은 I/O 작업입니다. 데이터베이스 통신은 네트워크 지연, 쿼리 처리, 디스크 접근으로 CPU 연산보다 훨씬 느립니다. N+1 쿼리는 이 문제를 증폭시키죠: 논리적 작업을 위해 수많은 개별 쿼리가 반복되며, 각 쿼리마다 왕복 시간이 누적됩니다.
초기 배치에서 청크(500개) 처리 시 PersonalizedRecommendationProcessor와 MemberWithHistoriesReader에서 병목이 발생했습니다. 각 회원 처리마다 시청 이력(MediaHitHistoryEntity)과 최근 7일 추천 이력을 개별 조회했기 때문입니다.
// PersonalizedRecommendationProcessor.java (개선 전)
@Override
public PersonalizedRecommendationEntity process(@NonNull MemberWithHistories item) {
final Long mbNo = item.getMember().getMbNo();
// N+1 쿼리 1: 시청 이력 (DTO 조합 과정에서 발생)
List<MediaHitHistoryEntity> mediaHistories = item.getHistories();
// N+1 쿼리 2: 최근 추천 이력
List<Long> recent7daysMeIdx = personalizedRecommendationJpaRepository.findRecentSomedayByMbNo(mbNo, LocalDateTime.now().minusDays(7));
// ...
}
청크당 500번의 findRecentSomedayByMbNo 호출과 시청 이력 조회로 데이터베이스 부하가 폭증했습니다. 다음 시퀀스 다이어그램이 이 비효율을 보여줍니다.
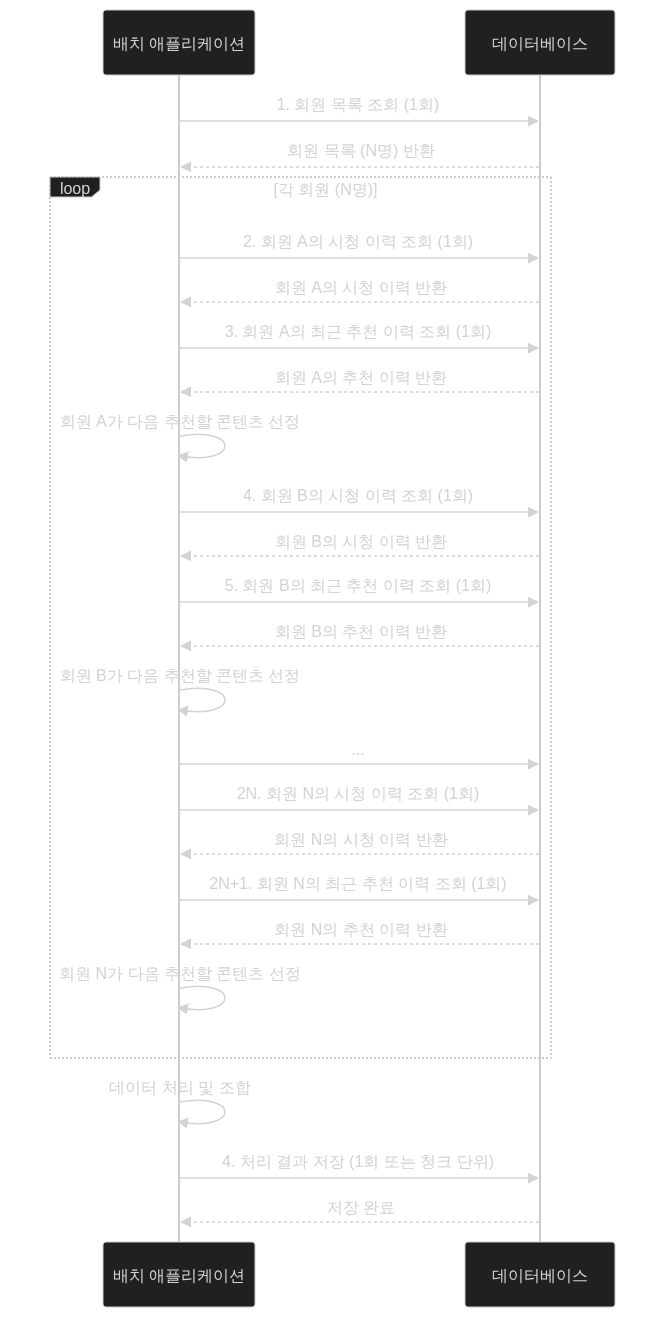
N명의 회원 처리에 1 + 2N 쿼리가 발생해 전체 시간이 기하급수적으로 증가했습니다. 이는 I/O-bound 작업으로, 3시간 이상 소요되는 배치를 초래했습니다.
4. 첫 번째 개선: Reader에서 데이터 일괄 조회로 N+1 해결
N+1을 피하기 위해 Reader에서 청크 단위로 모든 데이터를 미리 조회하도록 구조를 변경했습니다. Processor는 메모리 내 처리만 담당하게 됩니다.
4.1. 새로운 DTO와 Repository 메서드 정의
MemberProcessDto를 도입해 회원 정보, 시청 이력, 최근 추천 ID를 한 번에 담았습니다.
@Getter
public class MemberProcessDto {
private final MemberEntity member;
private final List<MediaHitHistoryEntity> histories;
private final List<Long> recentRecommendedMediaIds;
public MemberProcessDto(MemberEntity member, List<MediaHitHistoryEntity> histories, List<Long> recentRecommendedMediaIds) {
this.member = member;
this.histories = histories;
this.recentRecommendedMediaIds = recentRecommendedMediaIds;
}
}
Repository에 findRecentSomedayByMbNoIn 메서드를 추가해 여러 회원의 최근 추천을 일괄 조회합니다. 프로젝션 RecentRecommendationDto로 효율성을 높였습니다.
public interface PersonalizedRecommendationJpaRepository extends JpaRepository<PersonalizedRecommendationEntity, Long> {
interface RecentRecommendationDto {
Long getMbNo();
Long getMeIdx();
}
@Query("""
SELECT p.mbNo AS mbNo, p.meIdx AS meIdx
FROM PersonalizedRecommendationEntity p
WHERE p.mbNo IN :mbNos
AND p.createdAt >= :threshold
""")
List<RecentRecommendationDto> findRecentSomedayByMbNoIn(
@Param("mbNos") List<Long> mbNos,
@Param("threshold") LocalDateTime threshold
);
}
4.2. Reader 로직 수정
MemberWithHistoriesReader가 페이지 단위로 회원을 조회한 후, 시청 이력과 최근 추천을 일괄 가져와 DTO로 조합합니다.
@Slf4j
public class MemberWithHistoriesReader implements ItemReader<MemberProcessDto> {
// ... (생성자 및 필드)
private boolean fetchNextPage() {
EntityManager em = EntityManagerFactoryUtils.getTransactionalEntityManager(emf);
// 1. 회원 페이지 조회
List<MemberEntity> members = em.createQuery(
"SELECT m FROM MemberEntity m WHERE m.deletedAt IS NULL ORDER BY m.id ASC", MemberEntity.class)
.setFirstResult(page * pageSize)
.setMaxResults(pageSize)
.getResultList();
if (members.isEmpty()) return false;
List<Long> memberIds = members.stream().map(MemberEntity::getMbNo).collect(Collectors.toList());
// 2. 시청 이력 일괄 조회
Map<Long, List<MediaHitHistoryEntity>> historiesByMember = fetchHistoriesForMembers(em, memberIds);
// 3. 최근 추천 일괄 조회
Map<Long, List<Long>> recentRecommendationsByMember = fetchRecentRecommendationsForMembers(memberIds);
// 4. DTO 조합
this.results = new CopyOnWriteArrayList<>();
for (MemberEntity member : members) {
List<MediaHitHistoryEntity> histories = historiesByMember.getOrDefault(member.getMbNo(), Collections.emptyList());
List<Long> recentRecommendations = recentRecommendationsByMember.getOrDefault(member.getMbNo(), Collections.emptyList());
this.results.add(new MemberProcessDto(member, histories, recentRecommendations));
}
page++;
return !this.results.isEmpty();
}
// fetchHistoriesForMembers 및 fetchRecentRecommendationsForMembers 메서드 (생략)
}
4.3. Processor 및 Step 업데이트
Processor는 DTO에서 데이터를 직접 가져오며, Reader와 Step도 DTO 타입을 반영했습니다. (코드 생략, 이전과 유사)
이 변경으로 청크당 쿼리가 1001회에서 3회로 줄었습니다. 처리 시간은 1분에서 20초로 단축되었고, 전체 예상 시간은 3시간 20분에서 1시간으로 줄었습니다.
다음 시퀀스 다이어그램이 개선된 흐름을 보여줍니다.
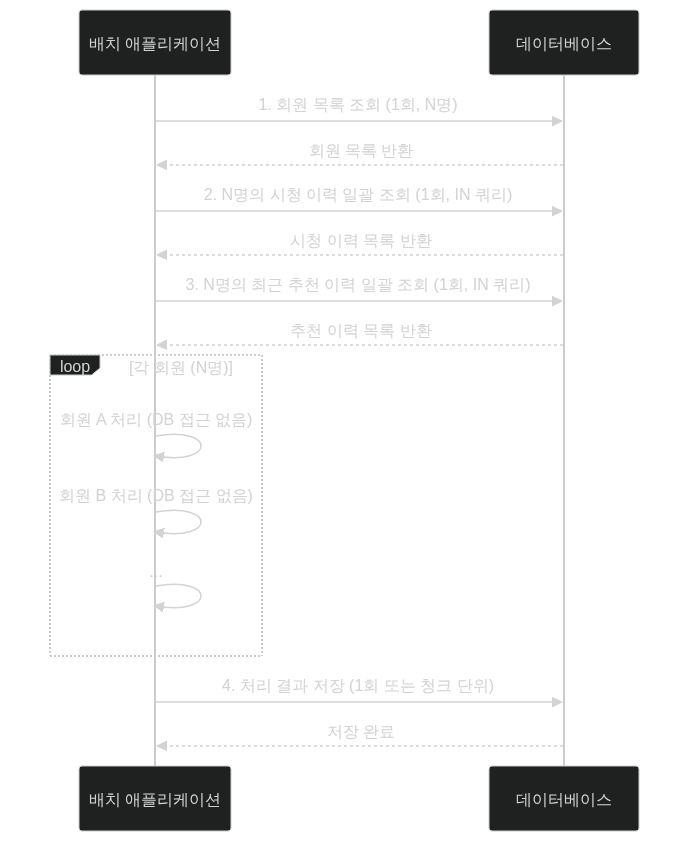
| 지표 | 개선 전 (청크 500개) | N+1 개선 후 (청크 500개) |
|---|---|---|
| 처리 시간 | 약 1분 | 약 20초 |
| 총 쿼리 수 | 약 1001회 | 약 3회 |
| 전체 예상 시간 | 3시간 20분 이상 | 약 1시간 |
그러나 여전히 1시간은 과도했습니다.
단순 쿼리 수로 비교하면 300배의 성능 향상이 예상됐어야 하는데, 60%가량만 개선된 점을 보니 N+1이 모든 문제의 원인은 아니었습니다. 실제 쿼리 로그를 분석하니, Reader/Processor가 아닌 Writer에서 추가 병목이 남아 있었습니다.
5. 두 번째 개선: Writer의 JDBC 배치 최적화
N+1 해결 후에도 Writer가 느린 이유를 파헤쳐보니, JdbcBatchItemWriter의 배치 삽입이 제대로 동작하지 않았습니다. 코드상으로는 addBatch() / executeBatch()가 호출되지만, MySQL JDBC 드라이버 설정 미비로 개별 INSERT가 실행되고 있었습니다.
@Bean
@Qualifier("personalizedRecommendationWriter")
public JdbcBatchItemWriter<PersonalizedRecommendationEntity> personalizedRecommendationJdbcWriter(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<PersonalizedRecommendationEntity>()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql("""
INSERT INTO personalized_recommendations
(recommendation_identity, created_at, updated_at, mb_no, m_idx, mc_type)
VALUES (:recommendationIdentity, :createdAt, :updatedAt, :mbNo, :meIdx, :mcType)
""")
.dataSource(dataSource)
.build();
}
JDBC URL에 rewriteBatchedStatements=true 옵션을 추가했습니다. 이로 인해 드라이버가 여러 INSERT를 하나의 멀티-밸류 INSERT로 재작성합니다.
PostgreSQL은 따로 옵션이 없어도 배치처리를 기본적으로 제공합니다만, MySQL은 JDBC URL에 명시를 반드시 해주어야 합니다.
-- 개선 전 (개별 INSERT)
INSERT INTO table (col1, col2) VALUES (val1, val2);
INSERT INTO table (col1, col2) VALUES (val3, val4);
-- 개선 후 (멀티-밸류 INSERT)
INSERT INTO table (col1, col2) VALUES (val1, val2), (val3, val4);
이 설정으로 Writer 성능이 폭발적으로 향상되었습니다. 전체 배치 시간이 1시간에서 3분으로 줄었습니다.
BATCH_STEP_EXECUTION 테이블 비교:
개선 전

- 3시간 11분 소요
최종 개선 후

- 3분 소요
| 지표 | N+1 개선 전 | N+1 개선 후 | JDBC 최적화 후 |
|---|---|---|---|
| 전체 처리 시간 | 약 3시간 20분 | 약 1시간 | 약 3분 |
| 총 쿼리 수 | 약 1001회/청크 | 약 3회/청크 | 동일 (쓰기 효율 ↑) |
| 비용 절감 | - | - | EC2 런타임 95% ↓ |
6. 결론
N+1 쿼리 문제를 Reader 일괄 조회로 해결한 후, Writer의 JDBC 설정을 최적화함으로써 Spring Batch 애플리케이션의 성능을 비약적으로 향상시켰습니다. 데이터베이스 부하 감소와 처리 시간 단축으로 서비스 지연과 비용을 동시에 줄였습니다.
향후 멀티 스레드 스텝이나 파티셔닝 같은 병렬 처리를 도입하면 더 나아질 수 있지만, 이번 개선으로 충분한 효과를 봤습니다. 배치 개발 시 RPW 구조의 I/O 최적화가 핵심임을 다시금 확인했습니다.
본 포스팅에서는 읽기 I/O를 줄이기 위해 N+1문제를 해결하고, 쓰기 I/O를 줄이기위해 배치쓰기를 제대로 활용하는 법에 대해 정리해보았습니다.
본문에서는 청크크기 500의 테스트 수치를 가지고 비교했지만, 저는 테스트 시 청크 크기 5000에서 가장 효율적인 결과를 얻었습니다. 하지만 이 수치는 정답이 아니며, 서비스의 데이터 구조와 트래픽 특성에 따라 최적의 청크 크기는 달라질 수 있습니다. 반드시 자체적인 성능 테스트를 통해 최적해를 도출하시기 바랍니다.
비용 비교 요약
| 항목 | 개선 전 (하루 3시간 20분 실행) | 개선 후 (하루 3분 실행) |
|---|---|---|
| EC2 종류 | t4g.small | t4g.small |
| 시간당 비용 | 24원 | 24원 |
| 일일 비용 | 약 80원 | 약 1.2원 |
| 월 비용(30일 기준) | 약 2,400원 | 약 36원 |
| 절감률 | - | 약 98.5% 절감 |
비용상으로는 그리 크지 않아보입니다만, 이로써 한 달에 한 번 까까를 공짜로 먹는 셈이 됐습니다.